Search Job APIs
The Search Job API provides third-party scripts and applications access to your log data through access key/access ID authentication.
Search Job APIs are not yet built with OpenAPI specifications and therefore not included in our Swagger docs. Instead, refer to the below documentation.
Prerequisites
The Search Job API is available to Enterprise accounts.
| Account Type | Account Level |
|---|---|
| Cloud Flex Legacy | Enterprise |
| Sumo Logic Credits | Trial, Enterprise Operations, Enterprise Security, Enterprise Suite |
Documentation
To get started with Sumo Logic APIs, see API Authentication, Endpoints, and Security.
Our APIs are built with OpenAPI. You can generate client libraries in several languages and explore automated testing.
To access our API documentation, navigate to the appropriate link based on your Sumo Logic deployment. Deployment types differ based on geographic location and account creation date. If unsure, see Which endpoint should I use?
Required role capabilities
To use the APIs in this resource, the user or account executing APIs must have the following role capabilities:
- Data Management
- Download Search Results
- View Collectors
- Security
- Manage Access Keys
Endpoints for API access
Sumo Logic has deployments that are assigned depending on the geographic location and the date an account is created. For API access, you must manually direct your API client to the correct Sumo Logic API URL.
See Sumo Logic Endpoints for the list of the URLs.
An HTTP 301 Moved error suggests that the wrong endpoint was specified.
Session Timeout
While the search job is running you need to request the job status based on the search job ID. The API keeps the search job alive by either polling for status every 20 to 30 seconds or gathering results. If the search job is not kept alive by API requests, it is canceled. When a search job is canceled for inactivity, you will get a 404 status.
You must enable cookies for subsequent requests to the search job. A 404 status (Page Not Found) on a follow-up request may be due to a cookie not accompanying the request.
There's a query timeout after eight hours, even if the API is polling and making requests. If you are running very few queries, you may be able to go a little longer, but you can expect most of your queries to end after eight hours.
So, a 404 status is generated in these two situations:
- When cookies are disabled.
- When a query session is canceled.
You can start requesting results asynchronously while the job is running and page through partial results while the job is in progress.
Search Job Result Limits
| Data Tier | Non-aggregate Search |
|---|---|
| Continuous | Can return up to 100K messages per search. |
| Frequent | Can return up to 100K messages per search. |
| Infrequent | Can return up to 100K messages per search. |
Flex Licensing model can return up to 100K messages per search.
If you need more results, you'll need to break up your search into several searches that span smaller blocks of the time range needed.
Rate limit throttling
- A rate limit of four API requests per second (240 requests per minute) applies to all API calls from a user.
- A rate limit of 10 concurrent requests to any API endpoint applies to an access key.
If a rate is exceeded, a rate limit exceeded 429 status code is returned.
A limit of 200 active concurrent search jobs applies to your organization.
When searching the Frequent Tier, a rate limit of 20 concurrent search jobs applies to your organization.
When searching the Flex data, a rate limit of 200 concurrent search jobs applies to your organization.
Once you reach the limit of 200 active searches, attempting an additional search will return a status code of 429 Too Many Requests, indicating that you've exceeded the permitted search job limit.
This limit applies only to Search Job API searches, and does not take into account searches run from the Sumo UI, scheduled searches, or dashboard panel searches that are running at the same time. If the search job is not kept alive by API requests every 20-30 seconds, it is canceled.
You can reduce the number of active search jobs by explicitly deleting a search after you receive the results. Manual deletion of searches helps maintain a low count of active searches, of reaching the Search Job API throttling limit. See Deleting a search job for details.
Process flow
The following figure shows the process flow for search jobs.
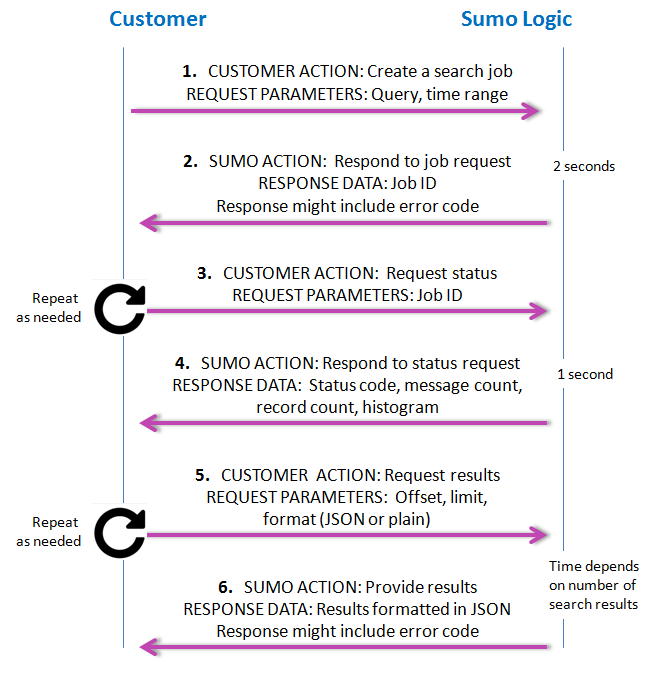
- Request. You request a search job, giving the query and time range.
- Response. Sumo Logic responds with a job ID. If there’s a problem with the request, an error code is provided (see the list of error codes following the figure).
- Request. Use the job ID to request search status. This needs to be done at least every 20-30 seconds so the search session is not canceled due to inactivity.
- Response. Sumo Logic responds with job status. An error code (404) is returned if the request could not be completed. The status includes the current state of the search job (gathering results, done executing, etc.). It also includes the message and record counts based on how many results have already been found while executing the search. For non-aggregation queries, only the number of messages is reported. For aggregation queries, the number of records produced is also reported. The search job status provides access to an implicitly generated histogram of the distribution of found messages over the time range specified for the search job. During and after execution, the API can be used to request available messages and records in a paging fashion.
- Request. You request results. It’s not necessary for the search to be complete for the user to request results; the process works asynchronously. You can repeat the request as often as needed to keep seeing updated results, keeping in mind the rate limits. The Search Job API can return 100K messages per search.
- Response. Sumo Logic delivers JSON-formatted search results as requested. The API can deliver partial results that the user can start paging through, even as new results continue to come in. If there’s a problem with the results, an error code is provided (see the list of error codes following the figure).
Errors
Generic errors that apply to all APIs
| Code | Error | Description |
| 301 | moved | The requested resource SHOULD be accessed through returned URI in Location Header. |
| 401 | unauthorized | Credential could not be verified. |
| 403 | forbidden | This operation is not allowed for your account type. |
| 404 | notfound | Requested resource could not be found. |
| 405 | method.unsupported | Unsupported method for URL. |
| 415 | contenttype.invalid | Invalid content type. |
| 429 | rate.limit.exceeded | The API request rate is higher than 4 request per second or your organization has exceeded the 200 active concurrent search job limit. |
| 500 | internal.error | Internal server error. |
| 503 | service.unavailable | Service is currently unavailable. |
Errors when creating the search query (#2 in the process flow)
| Code | Error | Description |
| 400 | generic | Generic error. |
| 400 | invalid.timestamp.to | The 'to' field contains an invalid time. |
| 400 | invalid.timestamp.from | The 'from' field contains an invalid time. |
| 400 | to.smaller.than.from | The 'from' time cannot be larger than the 'to' time. |
| 400 | unknown.timezone | The 'timezone' value is not a known time zone. See this Wikipedia article for a list of time zone codes. |
| 400 | empty.timezone | The 'timezone' cannot be blank. |
| 400 | no.query | No 'query' parameter was provided. |
| 400 | unknown.time.type | Time type is not correct. |
| 400 | parse.error | Unable to parse query. |
Error when requesting status (#3 in the process flow)
| Code | Error | Description |
| 404 | "jobid.invalid" | "Job ID is invalid." |
Errors when paging through the result set (#5 in the process flow)
| Code | Error | Description |
| 400 | "jobid.invalid" | "Job ID is invalid." |
| 400 | "offset.missing" | "Offset is missing." |
| 400 | "offset.negative" | "Offset cannot be negative." |
| 400 | "limit.missing" | "Limit is missing." |
| 400 | "limit.zero" | "Limit cannot be 0." |
| 400 | "limit.negative" | "Limit cannot be negative." |
| 400 | "no.records.not.an.aggregation.query" | "No records; query is not an aggregation" |
GET Methods
Get the current Search Job status
GET/v1/search/jobs/{SEARCH_JOB_ID}
Use the search job ID to obtain the current status of a search job (step 4 in the process flow). To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL. If you see To view all available endpoints, see Sumo Logic Endpoints.Which API endpoint should I use?
https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
Request parameters
| Parameter | Type | Required | Description |
| searchJobId | String | Yes | The ID of the search job. |
Result
The result is a JSON document containing the search job state, the number of messages found so far, the number of records produced so far, any pending warnings and errors, and any histogram buckets so far.
Sample session
curl -v --trace-ascii - -b cookies.txt -c cookies.txt -H 'Accept: application/json'
--user <ACCESSID>:<ACCESSKEY> https://api.sumologic.com/api/v1/search/jobs/37589506F194FC80
Which API endpoint should I use?
To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL.
If you see https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
To view all available endpoints, see Sumo Logic Endpoints.
This is the formatted result document:
{
"warning":"",
"state":"DONE GATHERING RESULTS",
"messageCount":90,
"histogramBuckets":[
{
"length":60000,
"count":1,
"startTimestamp":1359404820000
},
{
"length":60000,
"count":1,
"startTimestamp":1359405480000
},
{
"length":60000,
"count":1,
"startTimestamp":1359404340000
}
],
"pendingErrors":[
],
"pendingWarnings":[
],
"recordCount":1,
"usageDetails":{
"dataScannedInBytes":0
}
}
Notice that the state of the sample search job is DONE GATHERING RESULTS. The following table includes possible states.
| State | Description |
|---|---|
| NOT STARTED | Search job has not been started yet. |
| GATHERING RESULTS | Search job is still gathering more results, however results might already be available. |
| GATHERING RESULTS FROM SUBQUERIES | Search job is gathering results from the subqueries, before executing the main query. |
| FORCE PAUSED | Query that is paused by the system. It is true only for non-aggregate queries that are paused at the limit of 100k. This limit is dynamic and may vary from customer to customer. |
| DONE GATHERING RESULTS | Search job is done gathering results; the entire specified time range has been covered. |
| DONE GATHERING HISTOGRAM | Search job is done gathering results needed to build a histogram; the entire specified time range needed to build the histogram has been covered. |
| CANCELLED | The search job has been canceled. Note the spelling has two L letters. |
More about results
The warnings value contains the detailed information about the warning while obtaining the current status of a search job.
The messageCount and recordCount values indicate the number of messages and records found or produced so far. Messages are raw log messages and records are aggregated data.
For queries that do not contain an aggregation operator, only messages are returned. If the query contains an aggregation, for example, count by _sourceCategory, then the messages are returned along with records resulting from the aggregation (similar to what a SQL database would return).
The pendingErrors and pendingWarnings values contain any pending error or warning strings that have accumulated since the last time the status was requested.
The usageDetails value contains the amount of data scanned in bytes details.
Errors and warnings are not cumulative. If you need to retain the errors and warnings, store them locally.
The histogramBuckets value returns a list of histogram buckets. A histogram bucket is defined by its timestamp, which is the start timestamp (in milliseconds) of the bucket, and a length, also in milliseconds, that expressed the width of the bucket. The timestampplus length is the end timestamp of the bucket, so the count is the number of messages in the bucket.
The histogram buckets correspond to the histogram display in the Sumo Logic interactive analytics API. The histogram buckets are not cumulative. Because the status API will return only the new buckets discovered since the last status call, the buckets need to be remembered by the client, if they are to be used. A search job in the Sumo Logic backend will always execute a query by finding and processing matching messages starting at the end of the specified time range, and moving to the beginning. During this process, histogram buckets are discovered and returned.
Fields are not returned in the specified order and are all lowercase.
Paging through the messages found by a search job
GET/v1/search/jobs/{SEARCH_JOB_ID}/messages?offset={OFFSET}&limit={LIMIT}
The search job status informs the user about the number of found messages. The messages can be requested using a paging API call (step 6 in the process flow). Messages are always ordered by the latest To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL. If you see To view all available endpoints, see Sumo Logic Endpoints._messageTime value.Which API endpoint should I use?
https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
Request parameters
| Parameter | Type | Required | Description |
| searchJobId | String | Yes | The ID of the search job. |
| offset | Int | Yes | Return message starting at this offset. |
| limit | Int | Yes | The number of messages starting at offset to return. The maximum value for limit is 10,000 messages or 100 MB in total message size, which means the query may return less than 10,000 messages if you exceed the size limit. |
Sample session
curl -b cookies.txt -c cookies.txt -H 'Accept: application/json'
--user <ACCESSID>:<ACCESSKEY> 'https://api.sumologic.com/api/v1/search/jobs/37589506F194FC80/messages?offset=0&limit=10'
Which API endpoint should I use?
To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL.
If you see https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
To view all available endpoints, see Sumo Logic Endpoints.
This is the formatted result document (click to expand)
{
"warning": "",
"fields":[
{
"name":"_messageid",
"fieldType":"long",
"keyField":false
},
{
"name":"_sourceid",
"fieldType":"long",
"keyField":false
},
{
"name":"_sourceName",
"fieldType":"string",
"keyField":false
},
{
"name":"_sourceHost",
"fieldType":"string",
"keyField":false
},
{
"name":"_sourceCategory",
"fieldType":"string",
"keyField":false
},
{
"name":"_format",
"fieldType":"string",
"keyField":false
},
{
"name":"_size",
"fieldType":"long",
"keyField":false
},
{
"name":"_messagetime",
"fieldType":"long",
"keyField":false
},
{
"name":"_receipttime",
"fieldType":"long",
"keyField":false
},
{
"name":"_messagecount",
"fieldType":"int",
"keyField":false
},
{
"name":"_raw",
"fieldType":"string",
"keyField":false
},
{
"name":"_source",
"fieldType":"string",
"keyField":false
},
{
"name":"_collectorId",
"fieldType":"long",
"keyField":false
},
{
"name":"_collector",
"fieldType":"string",
"keyField":false
},
{
"name":"_blockid",
"fieldType":"long",
"keyField":false
}
],
"messages":[
{
"map":{
"_receipttime":"1359407350899",
"_source":"service",
"_collector":"local",
"_format":"plain:atp:o:0:l:29:p:yyyy-MM-dd HH:mm:ss,SSS ZZZZ",
"_blockid":"-9223372036854775669",
"_messageid":"-9223372036854773763",
"_messagetime":"1359407350333",
"_collectorId":"1579",
"_sourceName":"/Users/christian/Development/sumo/ops/assemblies/latest/service-20.1-SNAPSHOT/logs/service.log",
"_sourceHost":"Chiapet.local",
"_raw":"2013-01-28 13:09:10,333 -0800 INFO [module=SERVICE] [logger=util.scala.zk.discovery.AWSServiceRegistry] [thread=pool-1-thread-1] FINISHED findRunningInstances(ListBuffer((Service: name: elasticache-1, defaultProps: Map()), (Service: name: userAndOrgCache, defaultProps: Map()), (Service: name: rds_cloudcollector, defaultProps: Map()))) returning Map((Service: name: elasticache-1, defaultProps: Map()) -> [], (Service: name: userAndOrgCache, defaultProps: Map()) -> [], (Service: name: rds_cloudcollector, defaultProps: Map()) -> []) after 1515 ms",
"_size":"549",
"_sourceCategory":"service",
"_sourceid":"1640",
"_messagecount":"2044"
}
},
...
{
"map":{
"_receipttime":"1359407051885",
"_source":"service",
"_collector":"local",
"_format":"plain:atp:o:0:l:29:p:yyyy-MM-dd HH:mm:ss,SSS ZZZZ",
"_blockid":"-9223372036854775674",
"_messageid":"-9223372036854773772",
"_messagetime":"1359407049529",
"_collectorId":"1579",
"_sourceName":"/Users/christian/Development/sumo/ops/assemblies/latest/service-20.1-SNAPSHOT/logs/service.log",
"_sourceHost":"Chiapet.local",
"_raw":"2013-01-28 13:04:09,529 -0800 INFO [module=SERVICE] [logger=com.netflix.config.sources.DynamoDbConfigurationSource] [thread=pollingConfigurationSource] Successfully polled Dynamo for a new configuration based on table:raychaser-chiapetProperties",
"_size":"246",
"_sourceCategory":"service",
"_sourceid":"1640",
"_messagecount":"2035"
}
}
]
}
More about results
The result contains two lists, fields and messages.
- *warnings contains the detailed information about the warning while paging through the messages found by a search job.
- fields contains a list of all the fields defined for each of the messages returned. For each field, the field name and field type are returned.
- messages contains a list of maps, one map per message. Each map maps from the fields described in the fields list to the actual value for the message.
For example, the field _raw contains the raw collected log message.
_messageTime is the number of milliseconds since the epoch of the timestamp extracted from the message itself.
_receipttime is the number of milliseconds since the epoch of the timestamp of arrival of the message in the Sumo Logic system.
The metadata fields _sourceHost, _sourceName, and _sourceCategory, which are also featured in Sumo Logic, are available here.
Page through the records found by a Search Job
GET/v1/search/jobs/{SEARCH_JOB_ID}/records?offset={OFFSET}&limit={LIMIT}
The search job status informs the user as to the number of produced records, if the query performs an aggregation. Those records can be requested using a paging API call (step 6 in the process flow), just as the message can be requested. To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL. If you see To view all available endpoints, see Sumo Logic Endpoints.Which API endpoint should I use?
https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
Request parameters
| Parameter | Type | Required | Description |
| searchJobId | String | Yes | The ID of the search job. |
| offset | Int | Yes | Return records starting at this offset. |
| limit | Int | Yes | The number of records starting at offset to return. The maximum value for limit is 10,000 records. |
Sample session
curl -b cookies.txt -c cookies.txt -H
'Accept: application/json' --user <ACCESSID>:<ACCESSKEY>
'https://api.sumologic.com/api/v1/search/jobs/37589506F194FC80/records?offset=0&limit=1'
This is the formatted result document:
{
"warning": "",
"fields":[
{
"name":"_sourceCategory",
"fieldType":"string",
"keyField":true
},
{
"name":"_count",
"fieldType":"int",
"keyField":false
}
],
"records":[
{
"map":{
"_count":"90",
"_sourceCategory":"service"
}
}
]
}
The returned document is similar to the one returned for the message paging API. The schema of the records returned is described by the list of fields as part of the fields element. The records themselves are a list of maps.
The *warnings contains the detailed information about the warning while paging through the records found by a Search Job.
POST Methods
Create a search job
POST/v1/search/jobs
To create a search job (step 1 in the process flow), send a JSON request to the search job endpoint. JSON files need to be UTF-8 encoded following RFC 8259. To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL. If you see To view all available endpoints, see Sumo Logic Endpoints.Which API endpoint should I use?
https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
Headers
| Header | Value |
| Content-Type | application/json |
| Accept | application/json |
Request parameters
| Parameter | Type | Required | Description |
| query | String | Yes | The actual search expression. Make sure your query is valid JSON format following RFC 8259, you may need to escape certain characters. |
| from | String | Yes | The ISO 8601 date and time of the time range to start the search. For example, to specify July 16, 2017, use the form Can also be milliseconds since epoch. |
| to | String | Yes | The ISO 8601 date and time of the time range to end the search. For example, to specify July 26, 2017, use the form Can also be milliseconds since epoch. |
| timeZone | String | Yes | The time zone if from/to is not in milliseconds. See this Wikipedia article for a list of time zone codes. Note Alternatively, you can use the parameter timezone instead of timeZone. |
| byReceiptTime | Boolean | No | Define as true to run the search using receipt time. By default, searches do not run by receipt time. |
| autoParsingMode | String | No | This enables dynamic parsing. Values are: AutoParse - Sumo Logic will perform field extraction on JSON log messages when you run a search.Manual - (Default value) Sumo Logic will not autoparse JSON logs at search time. Note Previously, the supported values for this parameter were performance, intelligent, and verbose. These values still function, but are deprecated. Sumo Logic recommends the use of the new supported values: AutoParse and Manual. |
| requiresRawMessages | Boolean | No | Set as false to slightly improve the performance of aggregate queries as raw messages will not be generated. By default, the parameter value is set to true. |
Status codes
| Code | Text | Description |
| 202 | Accepted | The search job has been successfully created. |
| 400 | Bad Request | Generic request error by the client. |
| 415 | Unsupported Media Type | Content-Type wasn't set to application/json. |
Response headers
| Header | Value |
| Location | https://api.sumologic.com/api/v1/search/jobs/<SEARCH_JOB_ID> |
Result
A JSON document containing the ID of the newly created search job. The ID is a string to use for all API interactions relating to the search job.
Example error response:
{
"warning": "A 404 status (Page Not Found) on a follow-up request may be due to a cookie not accompanying the request",
"id": "IUUQI-DGH5I-TJ045",
"link": {
"rel": "self",
"href": "https://api.sumologic.com/api/v1/search/jobs/IUUQI-DGH5I-TJ045"
}
}
Sample session
The following sample session uses cURL. The Search Job API requires cookies to be honored by the client. Use curl -b cookies.txt -c cookies.txt options to receive, store, and send back the cookies set by the API.
curl -b cookies.txt -c cookies.txt -H 'Content-type: application/json'
-H 'Accept: application/json' -X POST -T createSearchJob.json
--user <ACCESSID>:<ACCESSKEY> https://api.sumologic.com/api/v1/search/jobs
Which API endpoint should I use?
To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL.
If you see https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
To view all available endpoints, see Sumo Logic Endpoints.
The createSearchJob.json file looks like this:
{
"query": "| count _sourceCategory",
"from": "2019-05-03T12:00:00",
"to": "2019-05-03T12:05:00",
"timeZone": "IST",
"byReceiptTime": true
}
The response from Sumo Logic returns the Search Job ID as the “Location” header in the format: https://api.sumologic.com/api/v1/search/jobs/[SEARCH_JOB_ID].
DELETE Methods
Delete a search job
DELETE/v1/search/jobs/{SEARCH_JOB_ID}
Although search jobs ultimately time out in the Sumo Logic backend, it's a good practice to explicitly cancel a search job when it is not needed anymore. To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL. If you see To view all available endpoints, see Sumo Logic Endpoints.Which API endpoint should I use?
https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
Request parameters
| Parameter | Type | Required | Description |
| searchJobId | String | Yes | The ID of the search job. |
Sample session
curl -b cookies.txt -c cookies.txt -X DELETE
-H 'Accept: application/json' --user <ACCESSID>:<ACCESSKEY>
https://api.sumologic.com/api/v1/search/jobs/37589506F194FC80
Which API endpoint should I use?
To determine which Sumo Logic API endpoint you should use, find the deployment pod referenced in your browser's Sumo Logic service URL.
If you see https://service.us2.sumologic.com, for example, that means you're running on the US2 pod and need to use the API endpoint https://api.us2.sumologic.com/api/. For the service URL https://service.eu.sumologic.com, you'd need to use the API endpoint https://api.eu.sumologic.com/api/, and so on. The only exception is the US1 pod (https://service.sumologic.com), which uses the API endpoint https://api.sumologic.com/api/.
To view all available endpoints, see Sumo Logic Endpoints.
Bash this Search Job
You can use the following script to exercise the API.
Ensure that you send ACCESSID/ACCESSKEY pair even if cookies are sent for the Search Job APIs.
#!/bin/bash
# Variables.
PROTOCOL=$1 # HTTPS is the only acceptable PROTOCOL
HOST=$2 # Use your Sumo endpoint as the HOST
ACCESSID=$3 # Authenticate with an access id and key
ACCESSKEY=$4
OPTIONS="--silent -b cookies.txt -c cookies.txt"
OPTIONS="-v -b cookies.txt -c cookies.txt"
OPTIONS="-v --trace-ascii -b cookies.txt -c cookies.txt"
Create a search job from a JSON file.
#
RESULT=$(curl $OPTIONS \
-H "Content-type: application/json" \
-H "Accept: application/json" \
-d @createSearchJob.json \
--user $ACCESSID:$ACCESSKEY \
"$PROTOCOL://$HOST/api/v1/search/jobs")
JOB_ID=$(echo $RESULT | perl -pe 's|.*"id":"(.*?)"[,}].*|\1|')
echo Search job created, id: $JOB_ID
# Wait until the search job is done.
STATE=""
until [ "$STATE" = "DONE GATHERING RESULTS" ]; do
sleep 5
RESULT=$(curl $OPTIONS \
-H "Accept: application/json" \
--user $ACCESSID:$ACCESSKEY \
"$PROTOCOL://$HOST/api/v1/search/jobs/$JOB_ID")
STATE=$(echo $RESULT | sed 's/.*"state":"\(.*\)"[,}].*/\1/')
MESSAGES=$(echo $RESULT | perl -pe 's|.*"messageCount":(.*?)[,}].*|\1|')
RECORDS=$(echo $RESULT | perl -pe 's|.*"recordCount":(.*?)[,}].*|\1|')
echo Search job state: $STATE, message count: $MESSAGES, record count: $RECORDS
done
# Get the first ten messages.
RESULT=$(curl $OPTIONS \
-H "Accept: application/json" \
--user $ACCESSID:$ACCESSKEY \
"$PROTOCOL://$HOST/api/v1/search/jobs/$JOB_ID/messages?offset=0&limit=10")
echo Messages:
echo $RESULT
# Get the first 2 records.
RESULT=$(curl $OPTIONS \
-H "Accept: application/json" \
--user $ACCESSID:$ACCESSKEY \
"$PROTOCOL://$HOST/api/v1/search/jobs/$JOB_ID/records?offset=0&limit=1")
echo Records:
echo $RESULT
# Delete the search job.
RESULT=$(curl $OPTIONS \
-X DELETE \
-H "Accept: application/json" \
--user $ACCESSID:$ACCESSKEY \
"$PROTOCOL://$HOST/api/v1/search/jobs/$JOB_ID")
JOB_ID=$(echo $RESULT | sed 's/^.*"id":"\(.*\)".*$/\1/')
echo Search job deleted, id: $JOB_ID