Kafka - Classic Collector

This guide provides an overview of Kafka related features and technologies. In addition, it contains recommendations on best practices, tutorials for getting started, and troubleshooting information for common situations.
The Sumo Logic App for Kafka is a unified logs and metrics app. The app helps you to monitor the availability, performance, and resource utilization of Kafka messaging/streaming clusters. Pre-configured dashboards provide insights into the cluster status, throughput, broker operations, topics, replication, zookeepers, node resource utilization, and error logs.
This App has been tested with following Kafka versions:
- 2.6.0
- 2.7.0
Sample log messages
- Kubernetes environments
- Non-Kubernetes environments
{
"timestamp":1617392000686,
"log":"[2021-04-02 19:33:20,598] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)",
"stream":"stdout",
"time":"2021-04-02T19:33:20.599066311Z"
}
[2021-03-10 20:12:28,742] INFO [KafkaServer id=0] \
started (kafka.server.KafkaServer)
Sample queries
This sample query string is from the Logs panel of the Kafka - Logs dashboard.
messaging_cluster=* messaging_system="kafka" \
| json auto maxdepth 1 nodrop | if (isEmpty(log), _raw, log) as kafka_log_message \
| parse field=kafka_log_message "[*] * *" as date_time,severity,msg | where severity in ("ERROR", "FATAL") \
| count by date_time, severity, msg | sort by date_time | limit 10
Collecting logs and metrics for Kafka
This section provides instructions for configuring log and metric collection for the Sumo Logic App for Kafka.
Configure collection for Kafka
Sumo Logic supports collection of logs and metrics data from Kafka in both Kubernetes and non-Kubernetes environments.
Click on the appropriate link below based on the environment where your Kafka clusters are hosted.
- Kubernetes environments
- Non-Kubernetes environments
In Kubernetes environments, we use the Telegraf Operator, which is packaged with our Kubernetes collection. You can learn more about it here. The following diagram illustrates how data is collected from Kafka in Kubernetes environments. In the following architecture, there are four services that make up the metric collection pipeline: Telegraf, Telegraf Operator, Prometheus, and Sumo Logic Distribution for OpenTelemetry Collector.
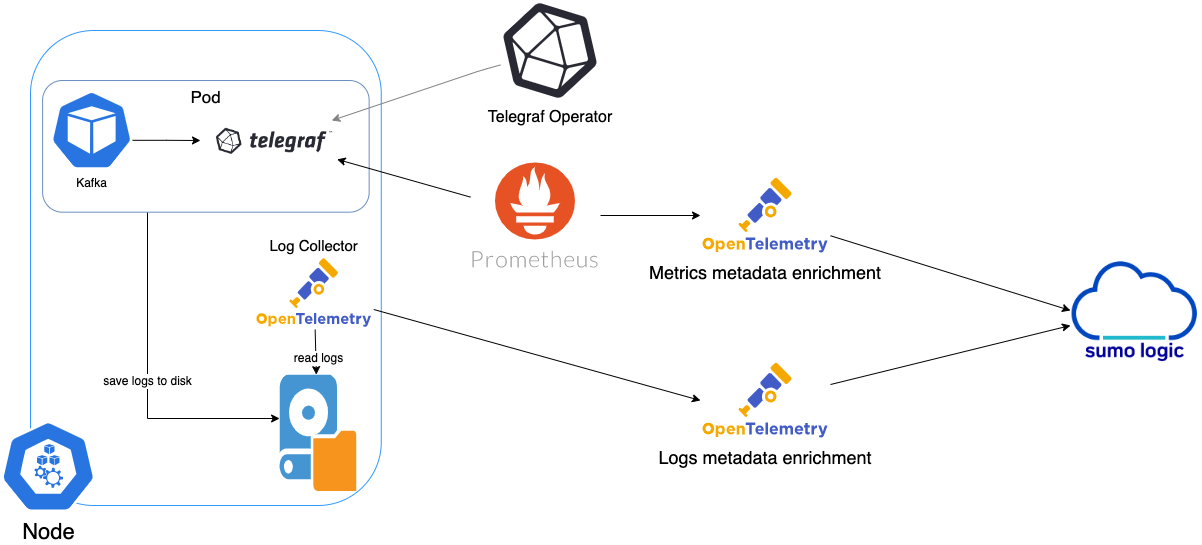
The first service in the pipeline is Telegraf. Telegraf collects metrics from Kafka. We’re running Telegraf in each pod we want to collect metrics from as a sidecar deployment. In other words, Telegraf runs in the same pod as the containers it monitors. Telegraf uses the Jolokia input pluginto obtain metrics, (For simplicity, the diagram doesn’t show the input plugins.) The injection of the Telegraf sidecar container is done by the Telegraf Operator. Prometheus pulls metrics from Telegraf and sends them to Sumo Logic Distribution for OpenTelemetry Collector which enriches metadata and sends metrics to Sumo Logic.
In the logs pipeline, Sumo Logic Distribution for OpenTelemetry Collector collects logs written to standard out and forwards them to another instance of Sumo Logic Distribution for OpenTelemetry Collector, which enriches metadata and sends logs to Sumo Logic.
Configure Metrics Collection
Follow these steps to collect metrics from a Kubernetes environment:
- Setup Kubernetes Collection with the Telegraf operator. Ensure that you are monitoring your Kubernetes clusters with the Telegraf operator enabled. If you are not, then follow these instructions to do so.
- Add annotations on your Kafka pods.
- Open this yaml file and add the annotations mentioned there.
- Enter in values for the parameters marked with
CHANGE_MEin the yaml file:
telegraf.influxdata.com/inputs. As telegraf will be run as a sidecar theurlsshould always be localhost.- In the input plugins section:
urls- The URL to the Kafka server. As telegraf will be run as a sidecar theurlsshould always be localhost. This can be a comma-separated list to connect to multiple Kafka servers.
- In the tags sections, (
[inputs.jolokia2_agent.tags]and[inputs.disk.tags]):environment. This is the deployment environment where the Kafka cluster identified by the value of servers resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.messaging_cluster. Enter a name to identify this Kafka cluster. This cluster name will be shown in the Sumo Logic dashboards.
Do not modify the following values as it will cause the Sumo Logic app to not function correctly.
telegraf.influxdata.com/class: sumologic-prometheus. This instructs the Telegraf operator what output to use. This should not be changed.prometheus.io/scrape: "true". This ensures our Prometheus plugin will scrape the metrics.prometheus.io/port: "9273". This tells Prometheus what ports to scrape metrics from. This should not be changed.telegraf.influxdata.com/inputs- In the tags sections
[inputs.jolokia2_agent/diskio/disk]component: “messaging”- This value is used by Sumo Logic apps to identify application components.messaging_system: “kafka”- This value identifies the database system.
- In the tags sections
For more information on all other parameters, see this doc for more parameters that can be configured in the Telegraf agent globally.
For more information on configuring the Joloka input plugin for Telegraf, see this doc.
- Configure your Kafka Pod to use the Jolokia Telegraf Input Plugin. Jolokia agent needs to be available to the Kafka Pods. Starting Kubernetes 1.10.0, you can store a binary file in a configMap. This makes it very easy to load the Jolokia jar file, and make it available to your pods.
- Download the latest version of the Jolokia JVM-Agent from Jolokia.
- Rename the file to
jolokia.jar. - Create a
configMap jolokiafrom the binary file:
kubectl create configmap jolokia --from-file=jolokia.jar
- Modify your Kafka Pod definition to include volume (type ConfigMap) and
volumeMounts. Finally, update theenv(environment variable) to start Jolokia, and apply the updated Kafka pod definition.
spec:
volumes:
- name: jolokia
configMap:
name: jolokia
containers:
- name: XYZ
image: XYZ
env:
- name: KAFKA_OPTS
value: "-javaagent:/opt/jolokia/jolokia.jar=port=8778,host=0.0.0.0"
volumeMounts:
- mountPath: "/opt/jolokia"
name: jolokia
- Verification Step: You can ssh to Kafka pod and run following commands to make sure Telegraf (and Jolokia) is scraping metrics from your Kafka Pod:
curl localhost:9273/metrics
curl http://localhost:8778/jolokia/list
echo $KAFKA_OPTS
It should give you the following result:
-javaagent:/opt/jolokia/jolokia.jar=port=8778,host=0.0.0.0
- Make sure jolokia.jar exists at /opt/jolokia/ directory of kafka pod. This is an example of what a Pod definition file looks like.
- Once this has been done, the Sumo Logic Kubernetes collection will automatically start collecting metrics from the pods having the labels and annotations defined in the previous step. Verify metrics are flowing into Sumo Logic by running the following metrics query:
component="messaging" and messaging_system="kafka"
Configure Logs Collection
This section explains the steps to collect Kafka logs from a Kubernetes environment.
- Collect Kafka logs written to standard output. If your Kafka helm chart/pod is writing the logs to standard output then follow the steps listed below to collect the logs:
- Apply the following labels to your Kafka pods:
environment: "prod-CHANGE_ME"
component: "messaging"
messaging_system: "kafka"
messaging_cluster: "kafka_prod_cluster01-CHANGE_ME” - Enter in values for the following parameters (marked in bold and
CHANGE_MEabove):environment. This is the deployment environment where the Kafka cluster identified by the value of servers resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.messaging_cluster. Enter a name to identify this Kafka cluster. This cluster name will be shown in the Sumo Logic dashboards.- Do not modify the following values as it will cause the Sumo Logic app to not function correctly.
component: “messaging”- This value is used by Sumo Logic apps to identify application components.messaging_system: “kafka”- This value identifies the messaging system.- For all other parameters, see this doc for more parameters that can be configured in the Telegraf agent globally.
- The Sumologic-Kubernetes-Collection will automatically capture the logs from stdout and will send the logs to Sumologic. For more information on deploying Sumologic-Kubernetes-Collection, see this page.
- Apply the following labels to your Kafka pods:
- Collect Kafka logs written to log files (Optional). If your Kafka helm chart/pod is writing its logs to log files, you can use a sidecar to send log files to standard out. To do this:
- Determine the location of the Kafka log file on Kubernetes. This can be determined from helm chart configurations.
- Install the Sumo Logic tailing sidecar operator.
- Add the following annotation in addition to the existing annotations.
Example:annotations:
tailing-sidecar: sidecarconfig;<mount>:<path_of_kafka_log_file>/<kafka_log_file_name>`annotations:
tailing-sidecar: sidecarconfig;data:/opt/Kafka/kafka_<VERSION>/logs/server.log- Make sure that the Kafka pods are running and annotations are applied by using the command:
kubectl describe pod <Kafka_pod_name>- Sumo Logic Kubernetes collection will automatically start collecting logs from the pods having the annotations defined above.
- FER to normalize the fields in Kubernetes environments. Labels created in Kubernetes environments automatically are prefixed with
pod_labels. To normalize these for our app to work, a Field Extraction Rule named AppObservabilityMessagingKafkaFER is automatically created.
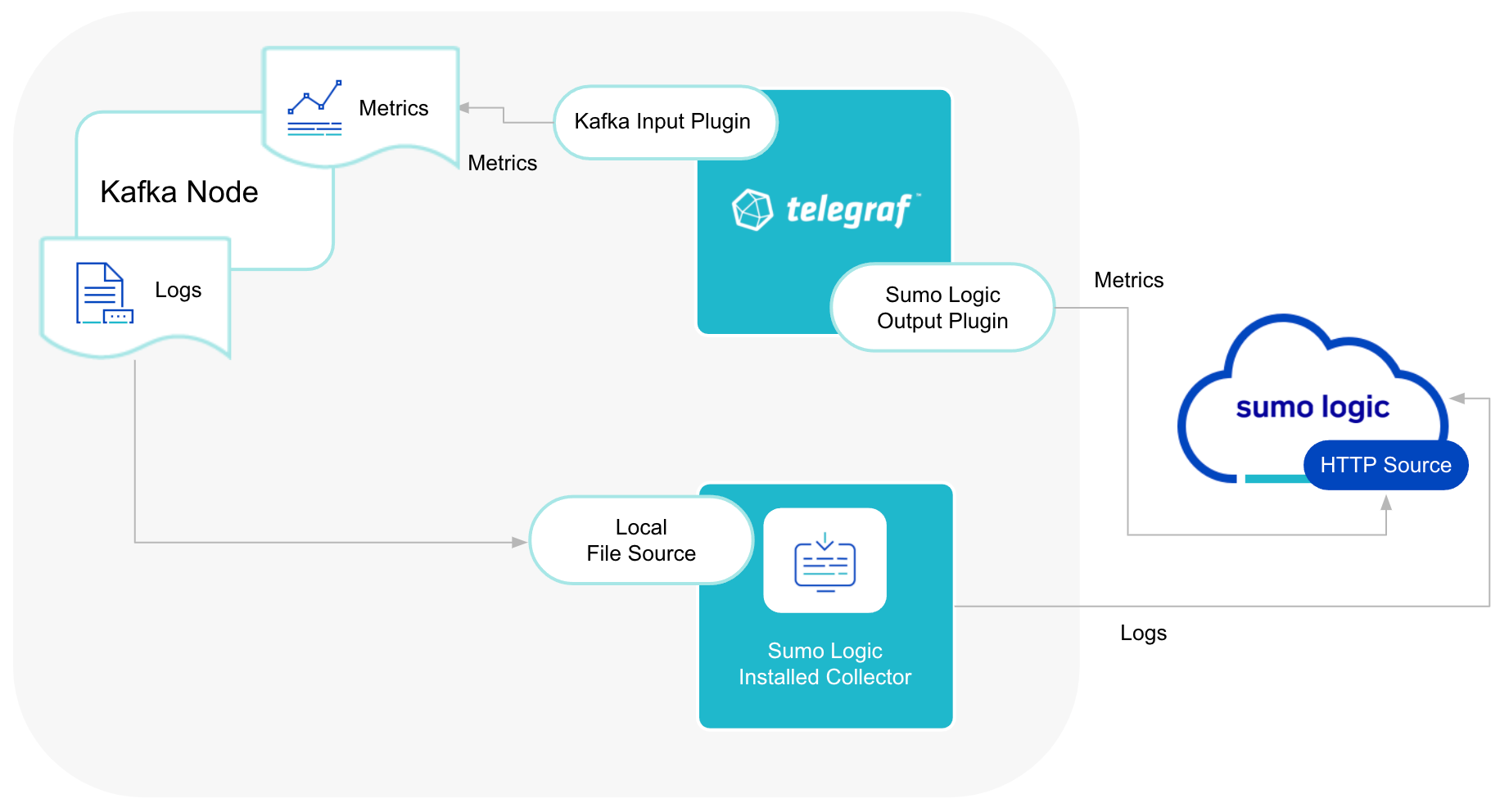
This section provides instructions for configuring log and metric collection for the Kafka app in Non-Kubernetes environments.
Prerequisite
Metrics collection setup can be done in two ways: using Telegraf with an installed collector; or by using OpenTelemetry. Both methods require you to configure Jolokia JVM Agent to collect metrics:
- Download the latest version of the Jolokia JVM-Agent from Jolokia.
- Rename downloaded Jar file to
jolokia-agent.jar. - Save the file
jolokia-agent.jaron your kafka server in/opt/kafka/libs. - Configure Kafka to use Jolokia by adding the following to
kafka-server-start.sh:
export JMX_PORT=9999
export RMI_HOSTNAME=0.0.0.0
export KAFKA_JMX_OPTS="-javaagent:/opt/kafka/libs/jolokia.jar=port=8778,host=$RMI_HOSTNAME -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=$RMI_HOSTNAME -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
- Restart Kafka Service.
- Verify that you can access jolokia on port 8778 using following command:
curl http://KAFKA_SERVER_IP_ADDRESS:8778/jolokia/
Using Telegraf and Installed Collector
We use the Telegraf Operator for Kafka metric collection and the Sumo Logic Installed Collector for collecting Kafka logs. The diagram below illustrates the components of the Kafka collection in a non-Kubernetes environment. Telegraf runs on the same system as Kafka, and uses the Kafka Jolokia input plugin to obtain Kafka metrics, and the Sumo Logic output plugin to send the metrics to Sumo Logic. Kafka Logs are sent to Sumo Logic Local File Source on Installed Collector.
This section provides instructions for configuring metrics collection for the Sumo Logic App for Kafka. Follow the instructions documented below to set up metrics collection for a given Broker in your Kafka Cluster:
Configure Collection of Kafka Metrics
- Configure a Hosted Collector. To create a new Sumo Logic hosted collector, perform the steps in the Configure a Hosted Collector section of the Sumo Logic documentation.
- Configure an HTTP Logs and Metrics Source. Create a new HTTP Logs and Metrics Source in the hosted collector created above by following these instructions. Make a note of the HTTP Source URL.
- Install Telegraf. Follow the steps in this document to install Telegraf on each Kafka Broker node.
- Configure and start telegraf. Create or modify the telegraf.conf file in /etc/telegraf/telegraf.d and copy and paste the text from this file.
- Please enter values for the following parameters (marked with
CHANGE_ME) in the downloaded file:
- In the input plugins section, which is
[[inputs.jolokia2_agent]]:urls- In the[[inputs.jolokia2_agent]]section. The URL to the Kafka server. This can be a comma-separated list to connect to multiple Kafka servers. Please see this doc for more information on additional parameters for configuring the Jolokia input plugin for Telegraf.- In the tags sections (total 3) which is section[inputs.jolokia2_agent.tags], and [inputs.disk.tags]
environment. This is the deployment environment where the Kafka cluster identified by the value ofurlsparameter resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.messaging_cluster. Enter a name to identify this Kafka cluster. This cluster name will be shown in the Sumo Logic dashboards.
- In the output plugins section:
url- This is the HTTP source URL created in step 3. Please see this doc for more information on additional parameters for configuring the Sumo Logic Telegraf output plugin.
Do not modify these values as they will cause the Sumo Logic apps to not function correctly:
data_format- “prometheus” In the output plugins section. In other words, this indicates that metrics should be sent in the Prometheus format to Sumo Logic.Component: “messaging” - In the input plugins section.In other words, this value is used by Sumo Logic apps to identify application components.messaging_system: “kafka” - In the input plugins sections.In other words, this value identifies the messaging system.component: “messaging” - In the input plugins sections. In other words, this value identifies application components.
Here is an example telegraf.conf file.
For all other parameters please see this doc for more properties that can be configured in the Telegraf agent globally. 6. Restart Telegraf. Once you have finalized your telegraf.conf file, you can start or reload the telegraf service using instructions from their doc.
At this point, Kafka metrics should start flowing into Sumo Logic.
Configure Collection of Kafka Logs on each Kafka Broker node
This section provides instructions for configuring log collection for Kafka running on a non-Kubernetes environment for the Sumo Logic App for Kafka. By default, Kafka logs are stored in a log file. Perform the steps outlined below for each Kafka Broker node.
- Configure logging in Kafka. By default Kafka logs (server.log and controller.log) are stored in the directory:
/opt/Kafka/kafka_<VERSION>/logs. Make a note of the above logs directory. - Configure an Installed Collector. To add an Installed collector, perform the steps as defined on the page Configure an Installed Collector.
- Configuring a Source. To add a Local File Source source for Kafka do the following:
- Add a Local File Source in the installed collector configured in the previous step.
- Configure the Local File Source fields as follows:
- Name. (Required)
- Description. (Optional)
- File Path (Required). Enter the path to your server.log and controller.log. The files are typically located in
/opt/Kafka/kafka_<VERSION>/logs/*.log. - Source Host. Sumo Logic uses the hostname assigned by the OS unless you enter a different host name
- Source Category. Enter any string to tag the output collected from this Source, such as Kafka/Logs. The Source Category metadata field is a fundamental building block to organize and label Sources. For details, see Best Practices.
- **Fields.**Set the following fields. For more information on fields please see this document:
component = messaging
messaging_system = kafka
messaging_cluster = <Your_KAFKA_Cluster_Name>
environment = <Environment_Name>, such as Dev, QA or Prod.
- Configure the Advanced section:
- Enable Timestamp Parsing. Select Extract timestamp information from log file entries.
- Time Zone. Choose the option, Ignore time zone from log file and instead use, and then select your Kafka Server’s time zone.
- Timestamp Format. The timestamp format is automatically detected.
- Encoding. Select UTF-8 (Default).
- Enable Multiline Processing. Detect messages spanning multiple lines
- Select Infer Boundaries - Detect message boundaries automatically
- Click Save.
At this point, Kafka logs should start flowing into Sumo Logic.
Using OpenTelemetry
We use the Telegraf receiver of Sumo Logic OpenTelemetry Distro Collector for Kafka metric collection and the Filelog receiver for collecting Kafka logs. Sumo Logic OT distro runs on the same system as Kafka, and uses the Kafka Jolokia input plugin for Telegraf to obtain Kafka metrics, and the Sumo Logic exporter to send the metrics to Sumo Logic. Kafka Logs are sent to Sumo Logic using the Filelog receiver.
Configure Collection of Kafka Metrics and Logs
- Install sumologic-otel-collector by following the instructions for your operating system:
- Configure and start
sumologic-otel-collector.
As part of collecting metrics data from Kafka, we will use the jolokia2 input plugin for Telegraf to get data from otel and then send data to Sumo Logic.
Create or modify config.yaml. Refer sample config here.
- Enter Sumo Logic collection details in the section; extensions > sumologic by referring to these instructions. Configure details like collector name, category, install token etc.
- Please enter values for the following parameters (marked with CHANGE_ME) in the downloaded file, reference here:
- In the receivers > telegraf > agent_config > input plugins section which is :
urls- In the section. The URL to the Kafka server. This can be a comma-separated list to connect to multiple Kafka servers. Please see this doc for more information on additional parameters for configuring the Jolokia input plugin for Telegraf.- In the tags sections (total 3) which is section
[inputs.jolokia2_agent.tags], and [inputs.disk.tags]environment. This is the deployment environment where the Kafka cluster identified by the value ofurlsparameter resides. For example: dev, prod or qa. While this value is optional we highly recommend setting it.messaging_cluster. Enter a name to identify this Kafka cluster. This cluster name will be shown in the Sumo Logic dashboards.
- In the receivers > filelog section, refer instructions here:
- include: list of kafka log files with full directory path.
- Configure sumologic exporter and service as defined here.
- In the receivers > telegraf > agent_config > input plugins section which is :
Do not modify these values as they will cause the Sumo Logic apps to not function correctly:
data_format- “prometheus” In the output plugins section. In other words, this indicates that metrics should be sent in the Prometheus format to Sumo Logic.Component: “messaging” - In the input plugins section.In other words, this value is used by Sumo Logic apps to identify application components.messaging_system: “kafka” - In the input plugins sections.In other words, this value identifies the messaging system.component: “messaging” - In the input plugins sections. In other words, this value identifies application components.
For all other parameters, see this doc for more properties that can be configured in the Telegraf agent globally.
- Run the Sumo Logic OT Distro using the below command
otelcol-sumo --config config.yaml
At this point, Kafka metrics and logs should start flowing into Sumo Logic.
Installing the Kafka app
To install the app, do the following:
Next-Gen App: To install or update the app, you must be an account administrator or a user with Manage Apps, Manage Monitors, Manage Fields, Manage Metric Rules, and Manage Collectors capabilities depending upon the different content types part of the app.
- Select App Catalog.
- In the 🔎 Search Apps field, run a search for your desired app, then select it.
- Click Install App.
note
Sometimes this button says Add Integration.
- Click Next in the Setup Data section.
- In the Configure section of your respective app, complete the following fields.
- Field Name. If you already have collectors and sources set up, select the configured metadata field name (eg _sourcecategory) or specify other custom metadata (eg: _collector) along with its metadata Field Value.
- Is K8S deployment involved. Specify if resources being monitored are partially or fully deployed on Kubernetes (K8s)
- Click Next. You will be redirected to the Preview & Done section.
Post-installation
Once your app is installed, it will appear in your Installed Apps folder, and dashboard panels will start to fill automatically.
Each panel slowly fills with data matching the time range query received since the panel was created. Results will not immediately be available but will be updated with full graphs and charts over time.
As part of the app installation process, the following fields will be created by default:
componentenvironmentmessaging_systemmessaging_clusterpod
If you're using Kafka in a Kubernetes environment, the following additional fields will be automatically created as a part of the app installation process:
pod_labels_componentpod_labels_environmentpod_labels_messaging_systempod_labels_messaging_cluster
Viewing the Kafka Dashboards
All dashboards have a set of filters that you can apply to the entire dashboard. Use these filters to drill down and examine the data to a granular level.
- You can change the time range for a dashboard or panel by selecting a predefined interval from a drop-down list, choosing a recently used time range, or specifying custom dates and times. Learn more.
- You can use template variables to drill down and examine the data on a granular level. For more information, see Filtering Dashboards with Template Variables.
- Most Next-Gen apps allow you to provide the scope at the installation time and are comprised of a key (
_sourceCategoryby default) and a default value for this key. Based on your input, the app dashboards will be parameterized with a dashboard variable, allowing you to change the dataset queried by all panels. This eliminates the need to create multiple copies of the same dashboard with different queries.
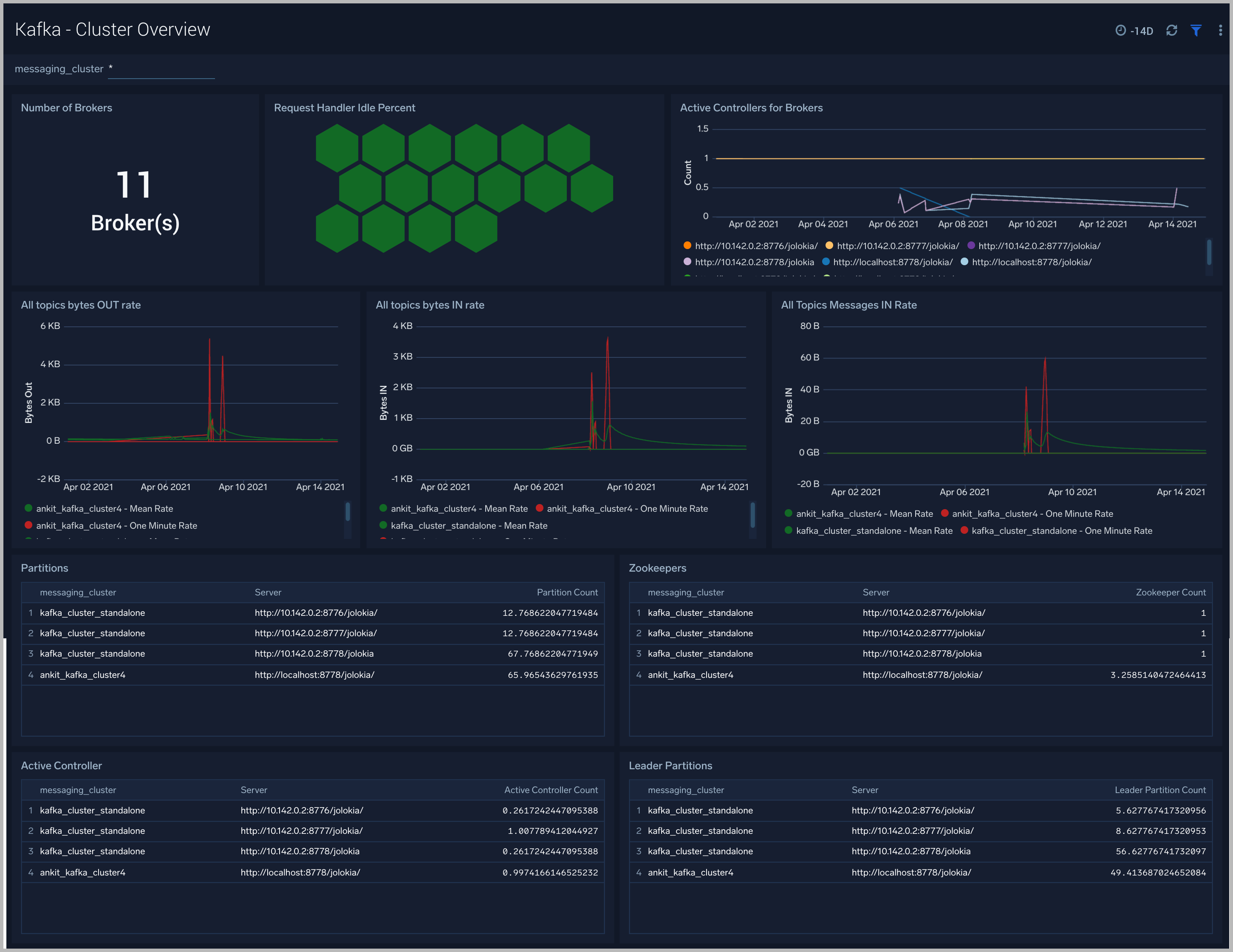
Kafka - Cluster Overview
The Kafka - Cluster Overview dashboard gives you an at-a-glance view of your Kafka deployment across brokers, controllers, topics, partitions and zookeepers.
Use this dashboard to:
- Identify when brokers don’t have active controllers
- Analyze trends across Request Handler Idle percentage metrics. Kafka’s request handler threads are responsible for servicing client requests ( read/write disk). If the request handler threads get overloaded, the time taken for requests to complete will be longer. If the request handler idle percent is constantly below 0.2 (20%), it may indicate that your cluster is overloaded and requires more resources.
- Determine the number of leaders, partitions and zookeepers across each cluster and ensure they match with expectations
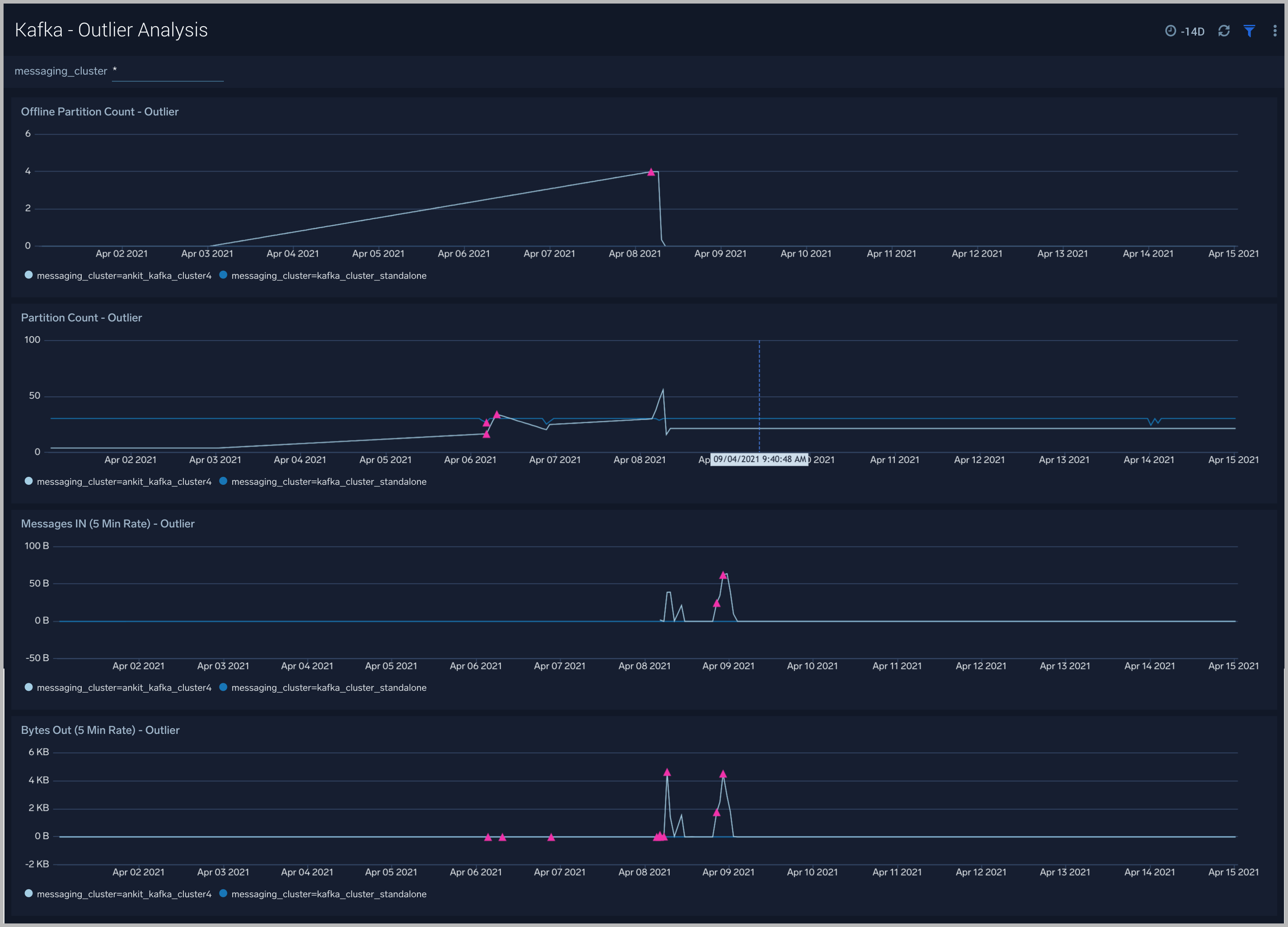
Kafka - Outlier Analysis
The Kafka - Outlier Analysis dashboard helps you identify outliers for key metrics across your Kafka clusters.
Use this dashboard to:
- To analyze trends, and quickly discover outliers across key metrics of your Kafka clusters
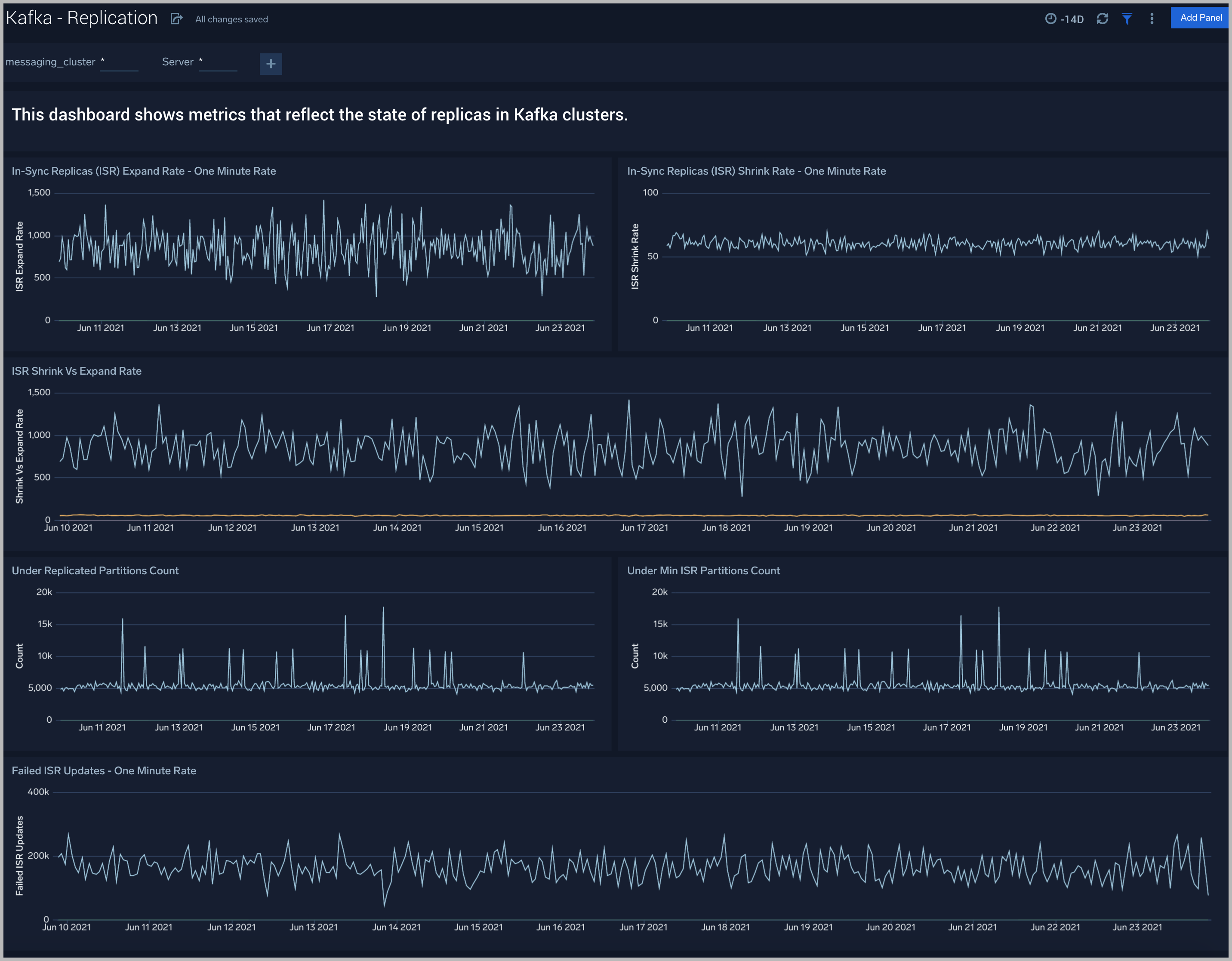
Kafka - Replication
The Kafka - Replication dashboard helps you understand the state of replicas in your Kafka clusters.
Use this dashboard to monitor the following key metrics:
- In-Sync Replicas (ISR) Expand Rate - The ISR Expand Rate metric displays the one-minute rate of increases in the number of In-Sync Replicas (ISR). ISR expansions occur when a broker comes online, such as when recovering from a failure or adding a new node. This increases the number of in-sync replicas available for each partition on that broker.The expected value for this rate is normally zero.
- In-Sync Replicas (ISR) Shrink Rate - The ISR Shrink Rate metric displays the one-minute rate of decreases in the number of In-Sync Replicas (ISR). ISR shrinks occur when an in-sync broker goes down, as it decreases the number of in-sync replicas available for each partition replica on that broker.The expected value for this rate is normally zero.
- ISR Shrink Vs Expand Rate - If you see a Spike in ISR Shrink followed by ISR Expand Rate - this may be because of nodes that have fallen behind replication and they may have either recovered or are in the process of recovering now.
- Failed ISR Updates
- Under Replicated Partitions Count
- Under Min ISR Partitions Count -The Under Min ISR Partitions metric displays the number of partitions, where the number of In-Sync Replicas (ISR) is less than the minimum number of in-sync replicas specified. The two most common causes of under-min ISR partitions are that one or more brokers are unresponsive, or the cluster is experiencing performance issues and one or more brokers are falling behind.
- The expected value for this rate is normally zero.
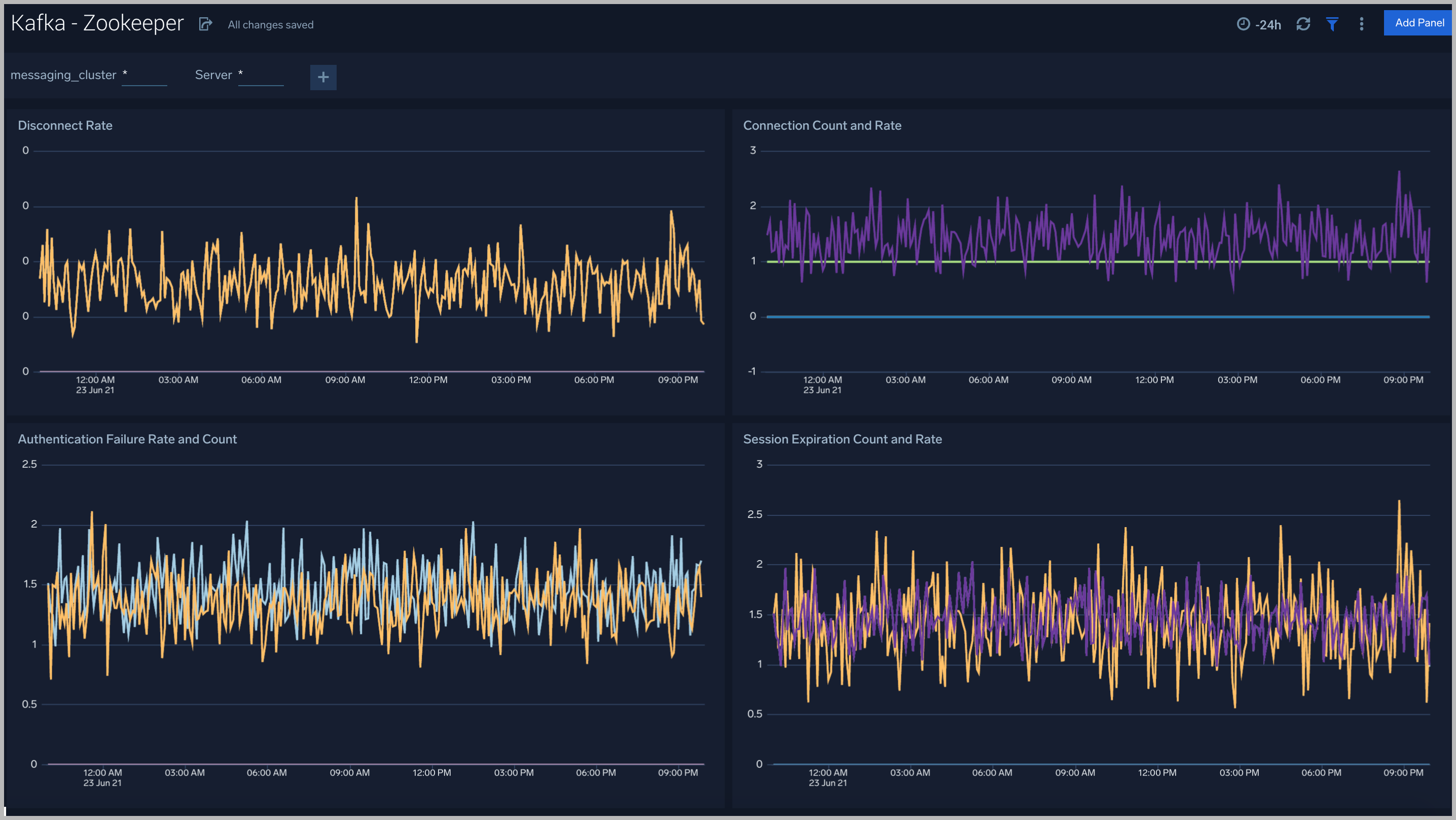
Kafka - Zookeeper
The Kafka -Zookeeper dashboard provides an at-a-glance view of the state of your partitions, active controllers, leaders, throughput and network across Kafka brokers and clusters.
Use this dashboard to monitor key Zookeeper metrics such as:
- Zookeeper disconnect rate - This metric indicates if a Zookeeper node has lostits connection to a Kafka broker.
- Authentication Failures - This metric indicates a Kafka Broker is unable to connect to its Zookeeper node.
- Session Expiration - When a Kafka broker - Zookeeper node session expires, leader changes can occur and the broker can be assigned a new controller. If this metric is increasing we recommend you:
- Check the health of your network.
- Check for garbage collection issues and tune your JVMs accordingly.
- Connection Rate.
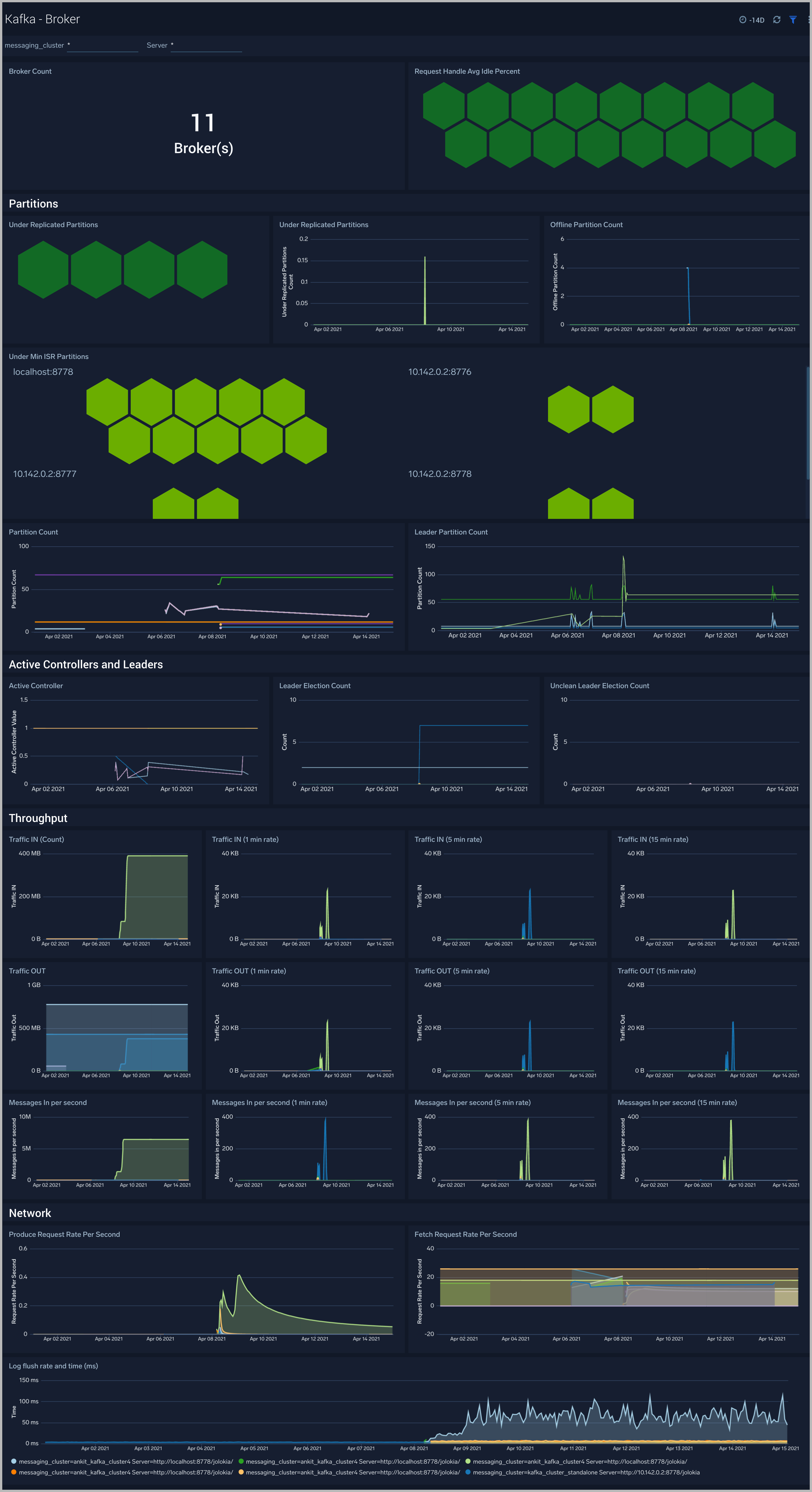
Kafka - Broker
The Kafka - Broker dashboard provides an at-a-glance view of the state of your partitions, active controllers, leaders, throughput, and network across Kafka brokers and clusters.
Use this dashboard to:
- Monitor Under Replicaed and offline partitions to quickly identify if a Kafka broker is down or over utilized.
- Monitor Unclean Leader Election count metrics - this metric shows the number of failures to elect a suitable leader per second. Unclean leader elections are caused when there are no available in-sync replicas for a partition (either due to network issues, lag causing the broker to fall behind, or brokers going down completely), so an out of sync replica is the only option for the leader. When an out of sync replica is elected leader, all data not replicated from the previous leader is lost forever.
- Monitor producer and fetch request rates.
- Monitor Log flush rate to determine the rate at which log data is written to disk
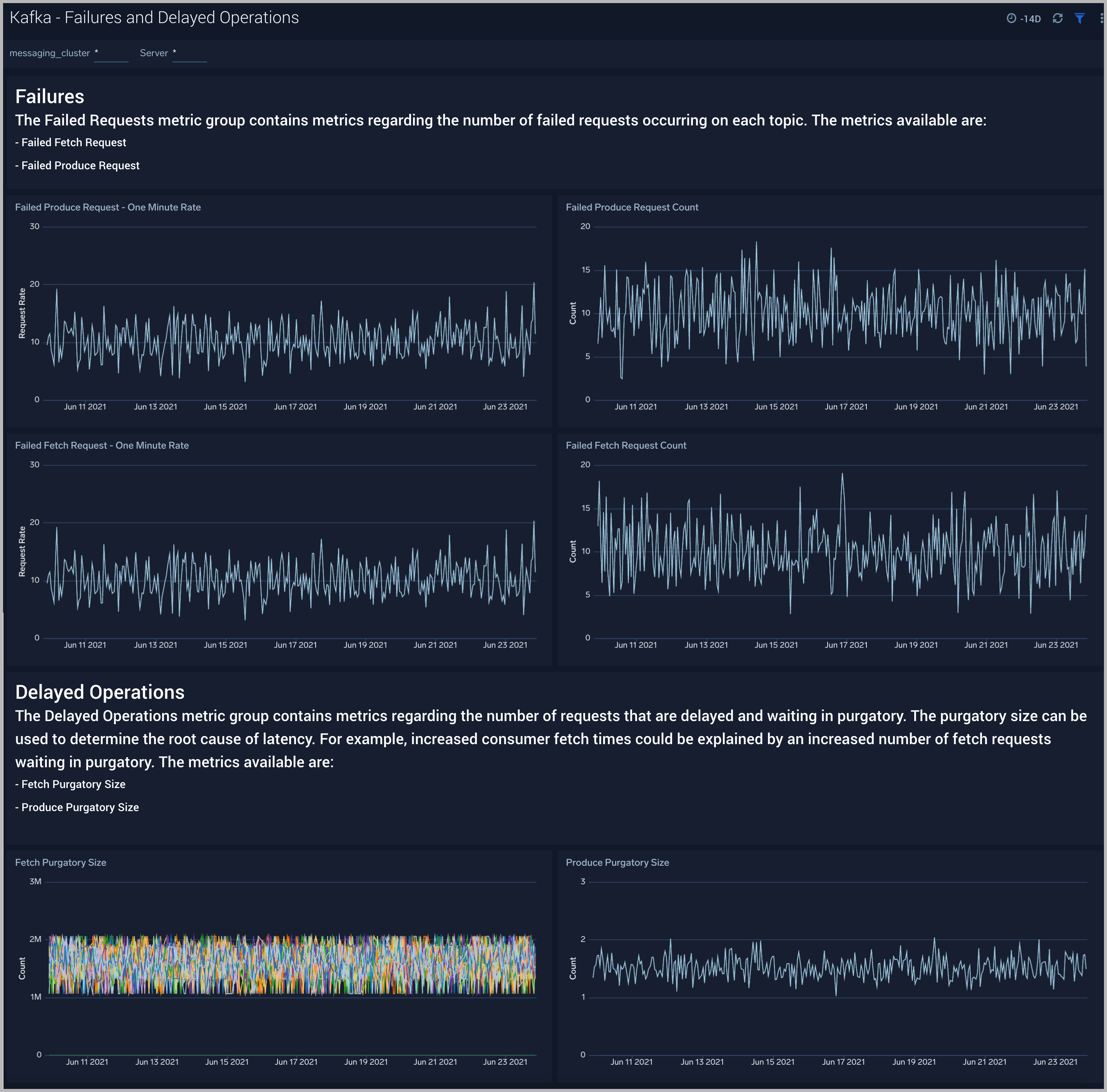
Kafka - Failures and Delayed Operations
The Kafka - Failures and Delayed Operations dashboard gives you insight into all failures and delayed operations associated with your Kafka clusters.
Use this dashboard to:
- Analyze failed produce requests - A failed produce request occurs when a problem is encountered when processing a produce request. This could be for a variety of reasons, however some common reasons are:
- The destination topic doesn’t exist (if auto-create is enabled then subsequent messages should be sent successfully).
- The message is too large.
- The producer is using request.required.acks=all or –1, and fewer than the required number of acknowledgements are received.
- Analyze failed Fetch Request - A failed fetch request occurs when a problem is encountered when processing a fetch request. This could be for a variety of reasons, but the most common cause is consumer requests timing out.
- Monitor delayed Operations metrics - This contains metrics regarding the number of requests that are delayed and waiting in purgatory. The purgatory size metric can be used to determine the root cause of latency. For example, increased consumer fetch times could be explained by an increased number of fetch requests waiting in purgatory. Available metrics are:
- Fetch Purgatory Size - The Fetch Purgatory Size metric shows the number of fetch requests currently waiting in purgatory. Fetch requests are added to purgatory if there is not enough data to fulfil the request (determined by fetch.min.bytes in the consumer configuration) and the requests wait in purgatory until the time specified by fetch.wait.max.ms is reached, or enough data becomes available.
- Produce Purgatory Size - The Produce Purgatory Size metric shows the number of produce requests currently waiting in purgatory. Produce requests are added to purgatory if request.required.acks is set to -1 or all, and the requests wait in purgatory until the partition leader receives an acknowledgement from all its followers. If the purgatory size metric keeps growing, some partition replicas may be overloaded. If this is the case, you can choose to increase the capacity of your cluster, or decrease the amount of produce requests being generated.
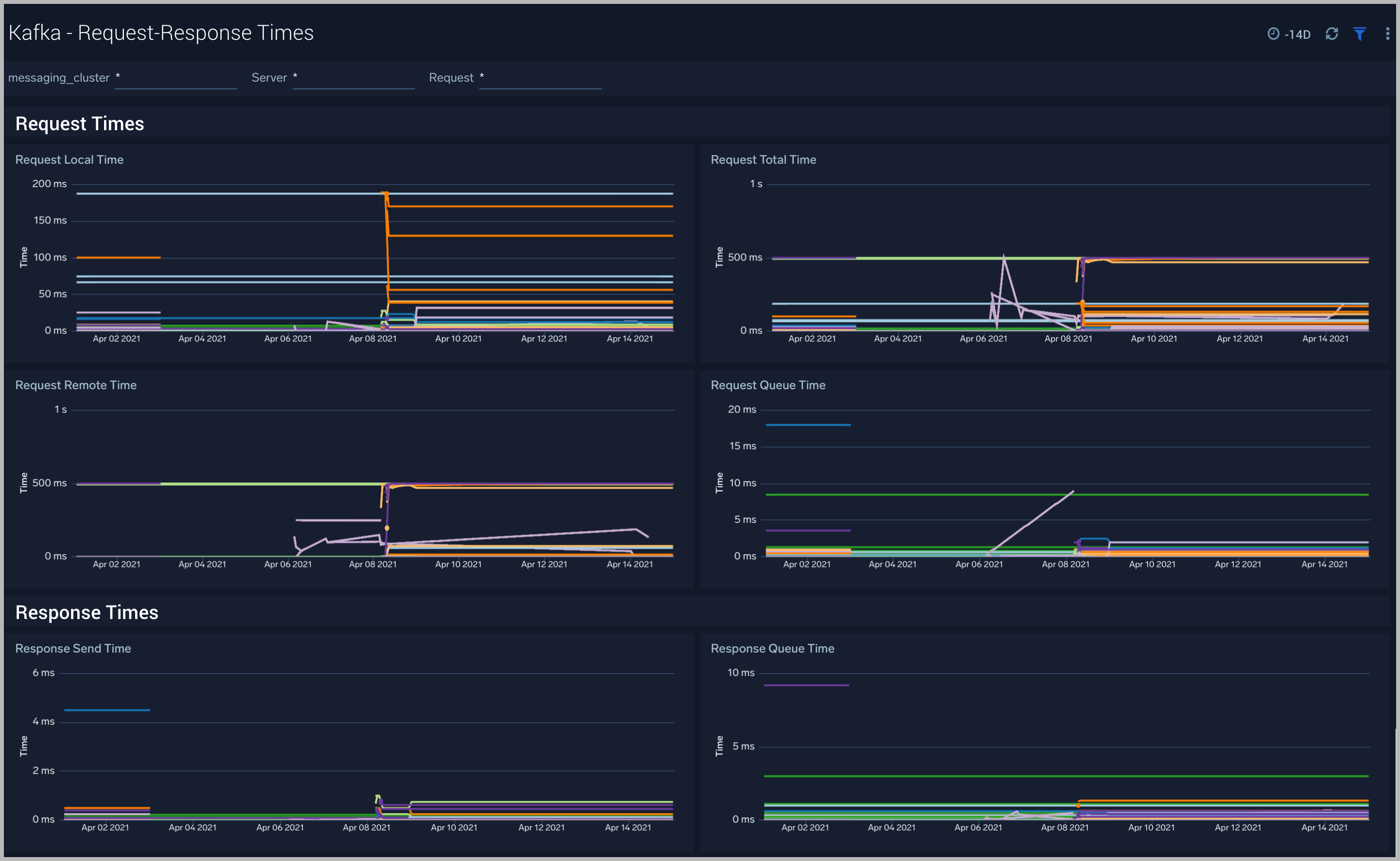
Kafka - Request-Response Times
The Kafka - Request-Response Times dashboard helps you get insight into key request and response latencies of your Kafka cluster.
Use this dashboard to:
- Monitor request time metrics - The Request Metrics metric group contains information regarding different types of request to and from the cluster. Important request metrics to monitor:
- Fetch Consumer Request Total Time - The Fetch Consumer Request Total Time metric shows the maximum and mean amount of time taken for processing, and the number of requests from consumers to get new data. Reasons for increased time taken could be: increased load on the node (creating processing delays), or perhaps requests are being held in purgatory for a long time (determined by fetch.min.bytes and fetch.wait.max.ms metrics).
- Fetch Follower Request Total Time - The Fetch Follower Request Total Time metric displays the maximum and mean amount of time taken while processing, and the number of requests to get new data from Kafka brokers that are followers of a partition. Common causes of increased time taken are increased load on the node causing delays in processing requests, or that some partition replicas may be overloaded or temporarily unavailable.
- Produce Request Total Time- The Produce Request Total Time metric displays the maximum and mean amount of time taken for processing, and the number of requests from producers to send data. Some reasons for increased time taken could be: increased load on the node causing delays in processing the requests, or perhaps requests are being held in purgatory for a long time (if the
requests.required.acksmetrics is equal to '1' or all).
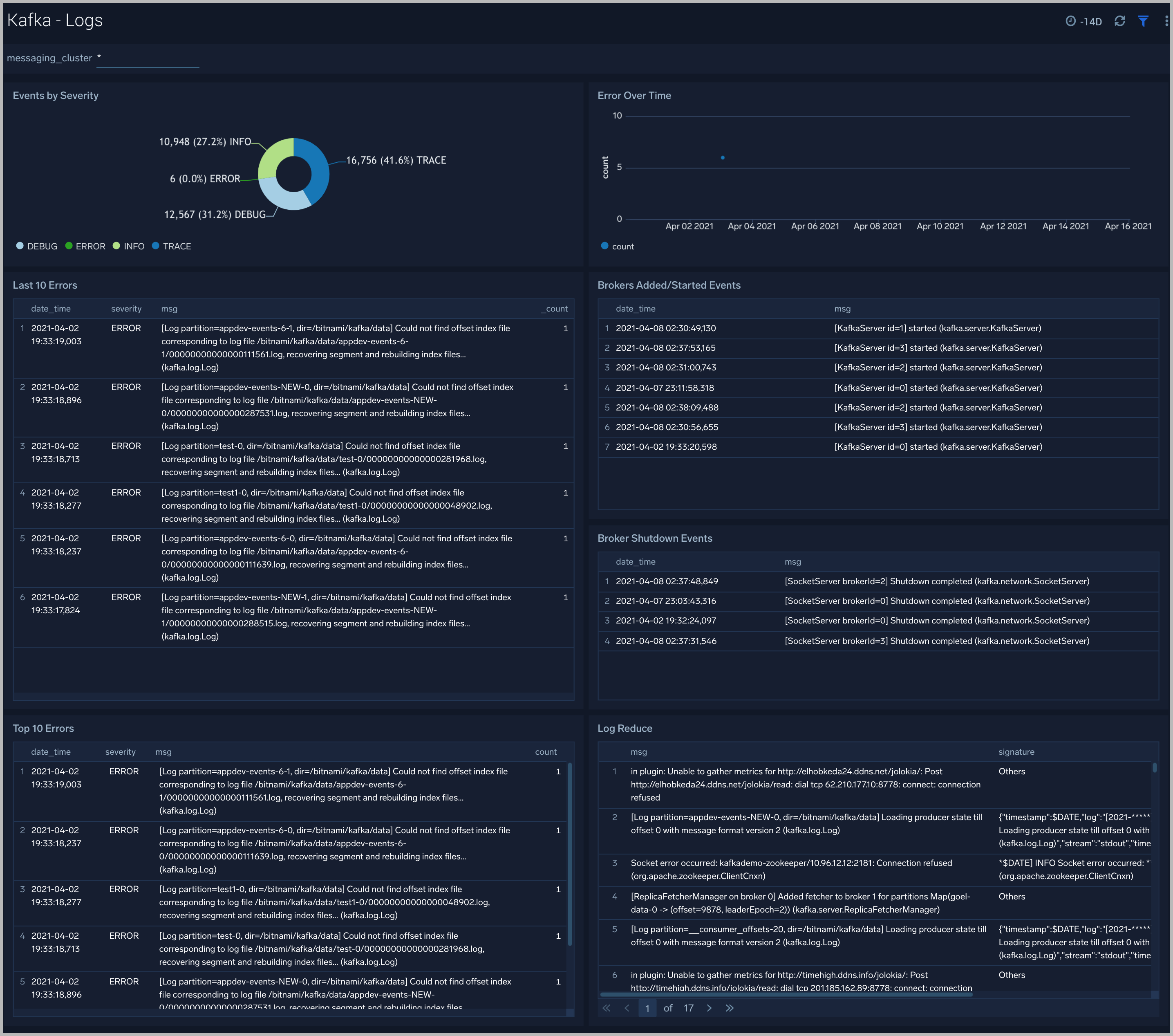
Kafka - Logs
This dashboard helps you quickly analyze your Kafka error logs across all clusters.
Use this dashboard to:
- Identify critical events in your Kafka broker and controller logs;
- Examine trends to detect spikes in Error or Fatal events
- Monitor Broker added/started and shutdown events in your cluster.
- Quickly determine patterns across all logs in a given Kafka cluster.
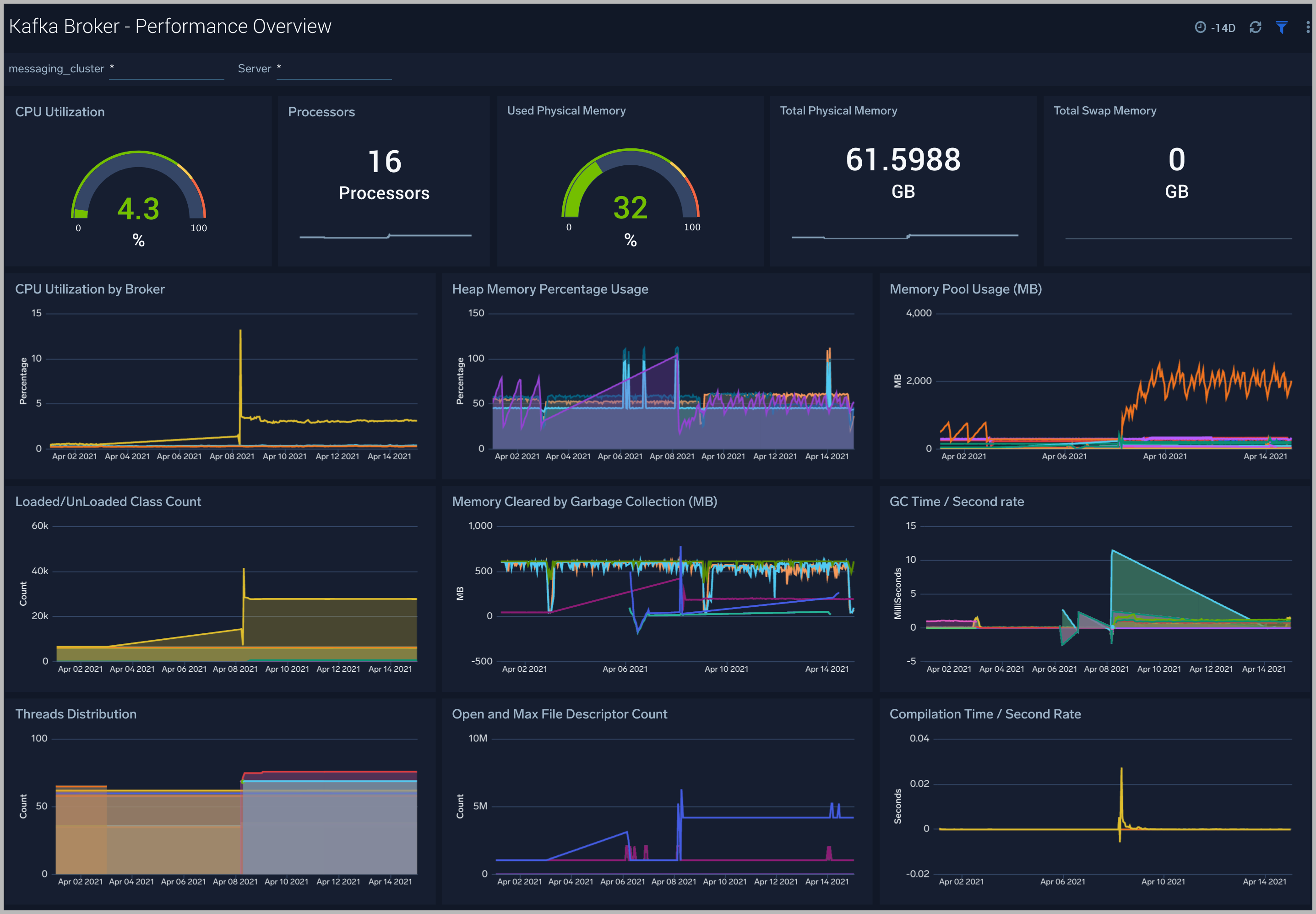
Kafka Broker - Performance Overview
The Kafka Broker - Performance Overview dashboards helps you Get an at-a-glance view of the performance and resource utilization of your Kafka brokers and their JVMs.
Use this dashboard to:
- Monitor the number of open file descriptors. If the number of open file descriptors reaches the maximum file descriptor, it can cause an IOException error
- Get insight into Garbage collection and its impact on CPU usage and memory
- Examine how threads are distributed
- Understand the behavior of class count. If class count keeps on increasing, you may have a problem with the same classes loaded by multiple classloaders.
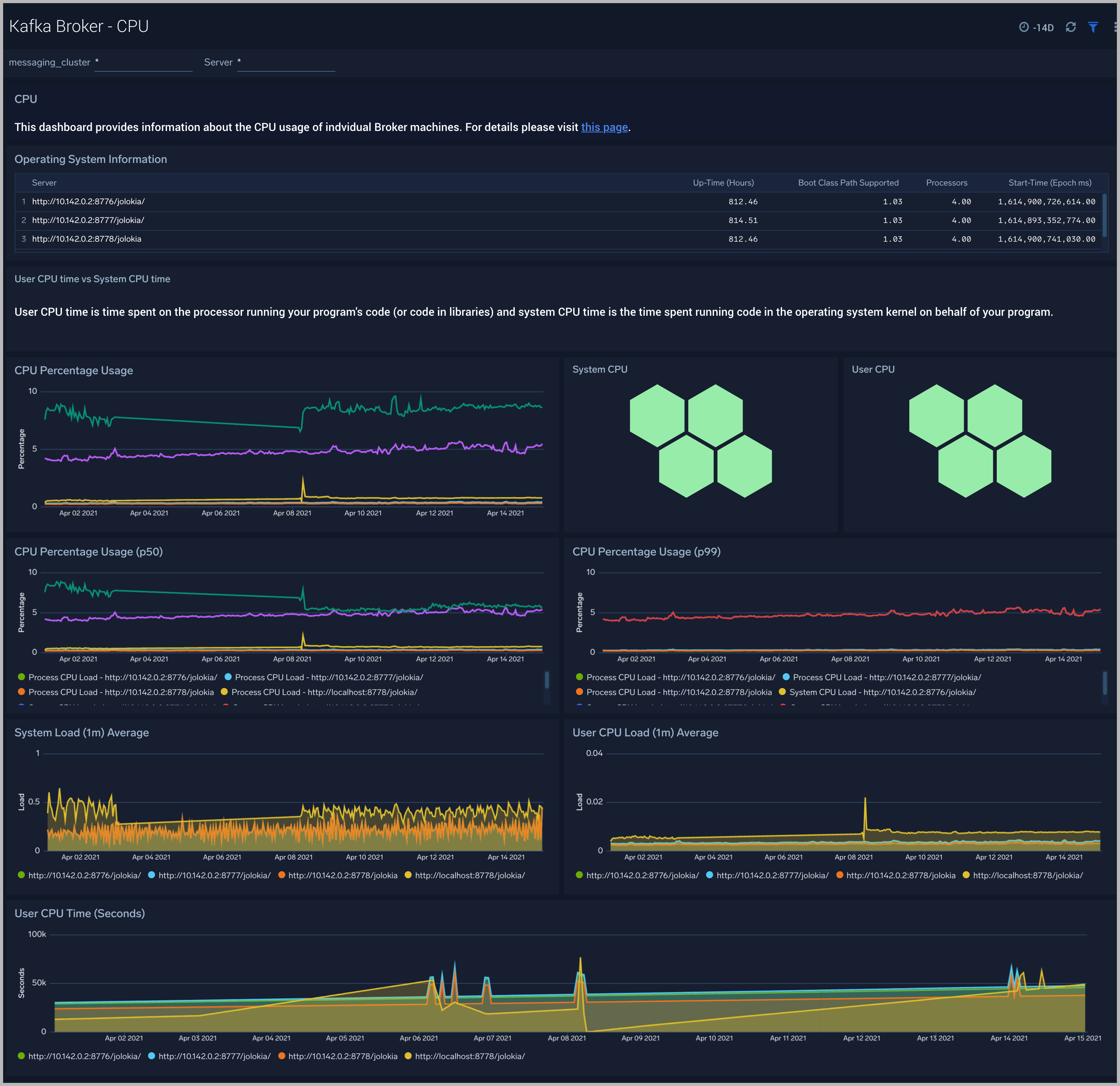
Kafka Broker - CPU
The Kafka Broker - CPU dashboard shows information about the CPU utilization of individual Broker machines.
Use this dashboard to:
- Get insights into the process and user CPU load of Kafka brokers. High CPU utilization can make Kafka flaky and can cause read/write timeouts.
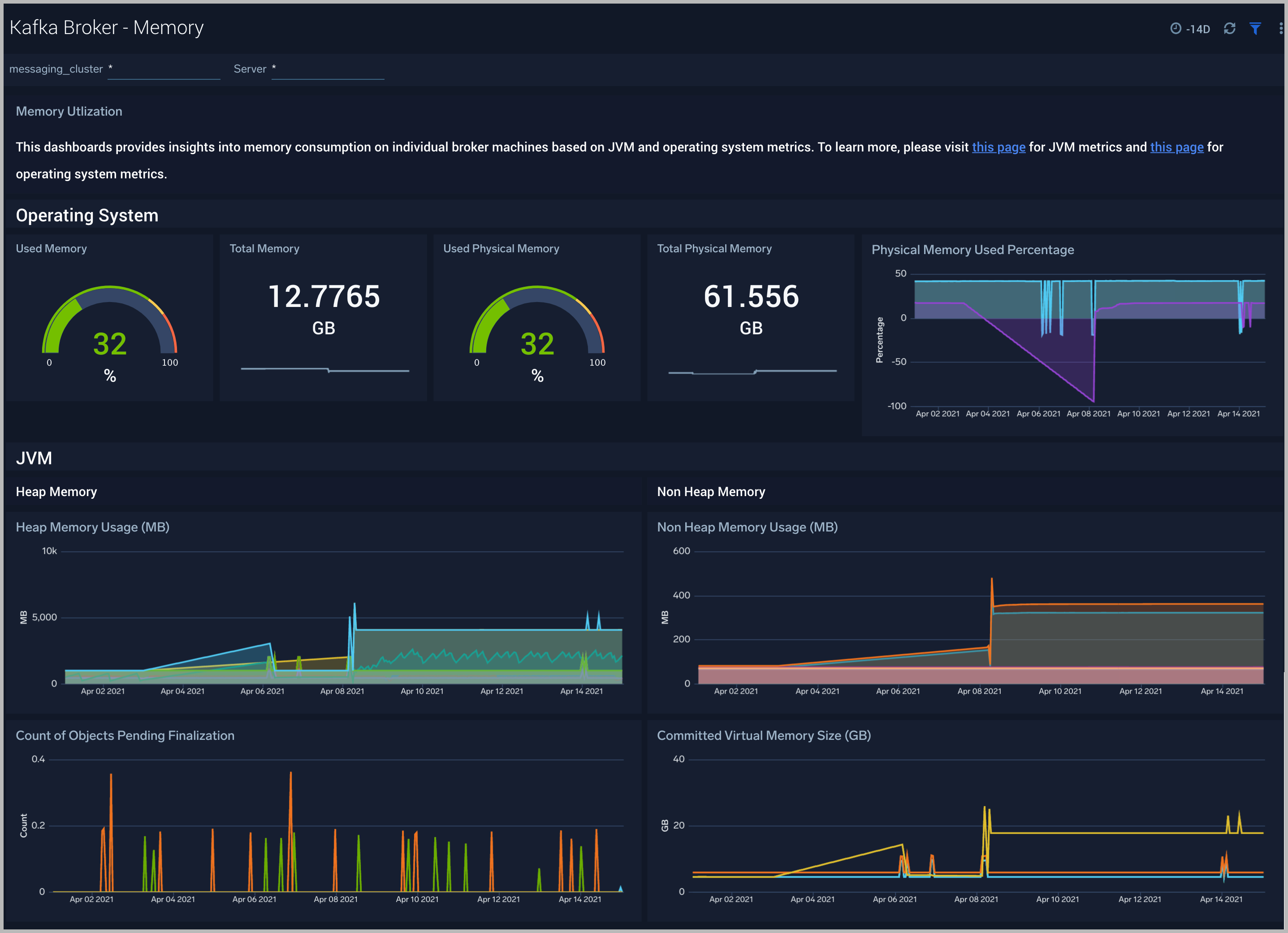
Kafka Broker - Memory
The Kafka Broker - Memory dashboard shows the percentage of the heap and non-heap memory used, physical and swap memory usage of your Kafka broker’s JVM.
Use this dashboard to:
- Understand how memory is used across Heap and Non-Heap memory.
- Examine physical and swap memory usage and make resource adjustments as needed.
- Examine the pending object finalization count which when high can lead to excessive memory usage.
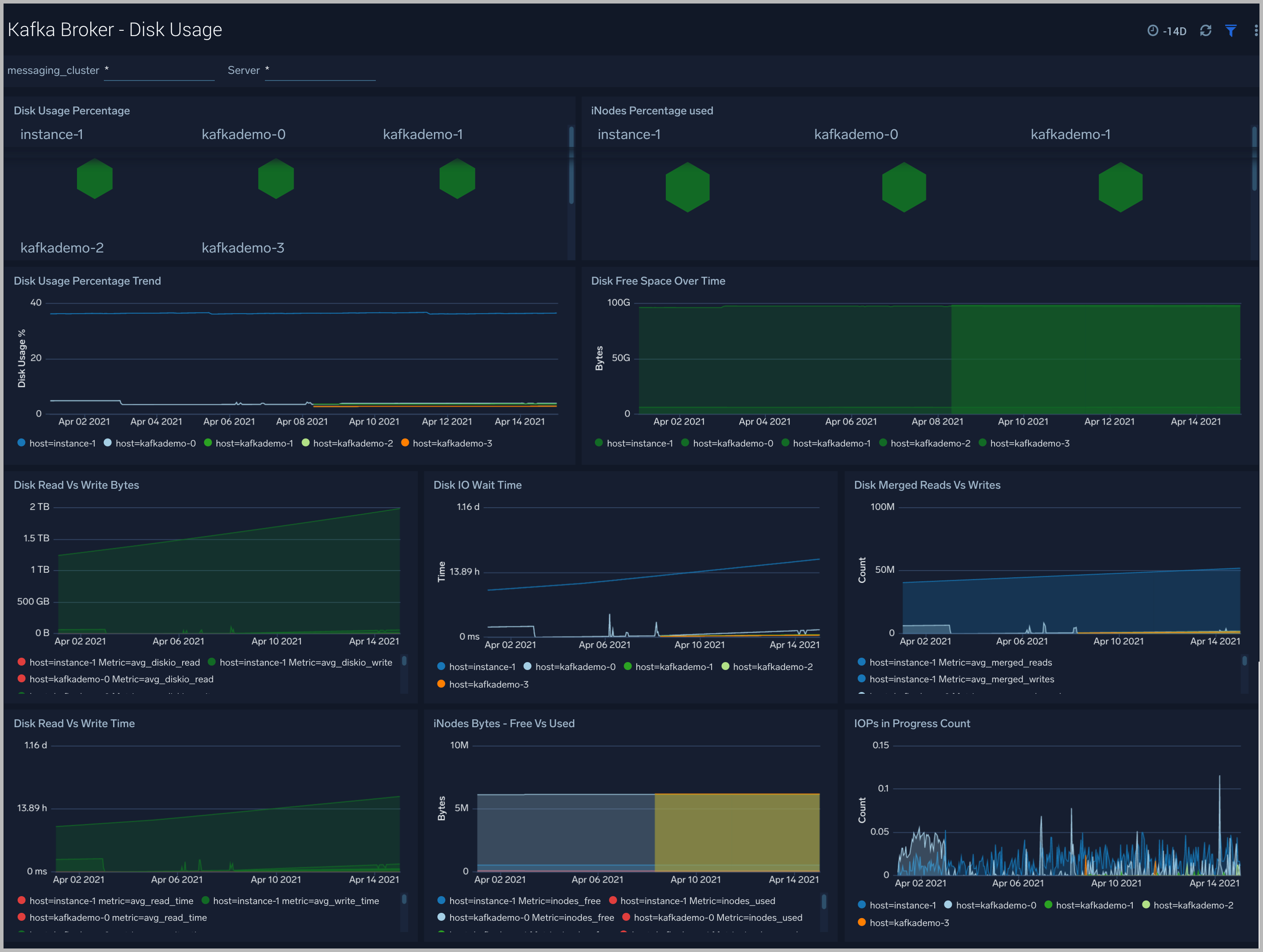
Kafka Broker - Disk Usage
The Kafka Broker - Disk Usage dashboard helps monitor disk usage across your Kafka Brokers.
Use this dashboard to:
- Monitor Disk Usage percentage on Kafka Brokers. This is critical as Kafka brokers use disk space to store messages for each topic. Other factors that affect disk utilization are:
- Topic replication factor of Kafka topics.
- Log retention settings.
- Analyze trends in disk throughput and find any spikes. This is especially important as disk throughput can be a performance bottleneck.
- Monitor iNodes bytes used, and disk read vs writes. These metrics are important to monitor as Kafka may not necessarily distribute data from a heavily occupied disk, which itself can bring the Kafka down.
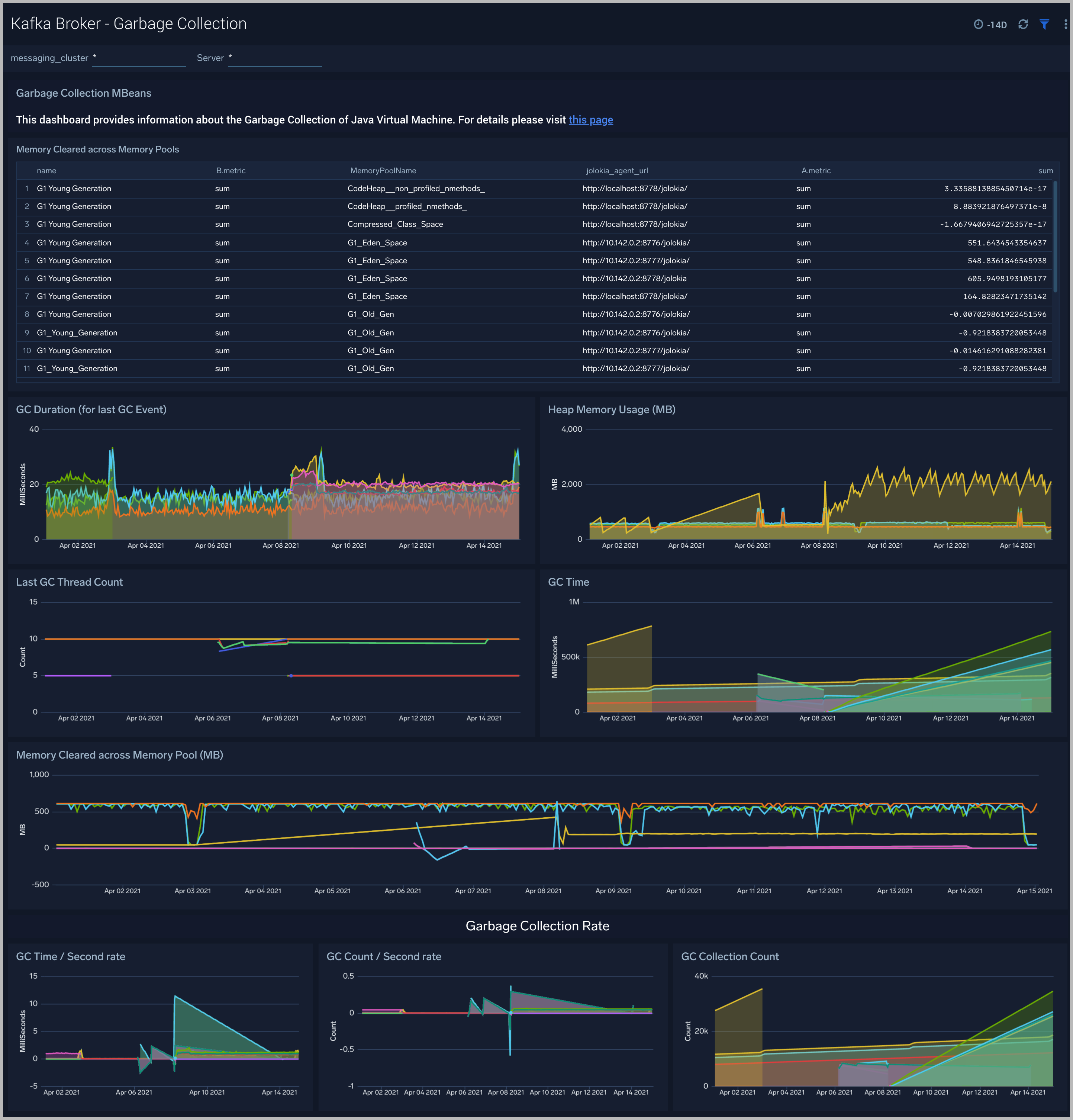
Kafka Broker - Garbage Collection
The Kafka Broker - Garbage Collection dashboard shows key Garbage Collector statistics like the duration of the last GC run, objects collected, threads used, and memory cleared in the last GC run of your java virtual machine.
Use this dashboard to:
- Understand the amount of time spent in garbage collection. If this time keeps increasing, your Kafka brokers may have more CPU usage.
- Understand the amount of memory cleared by garbage collectors across memory pools and their impact on the Heap memory.
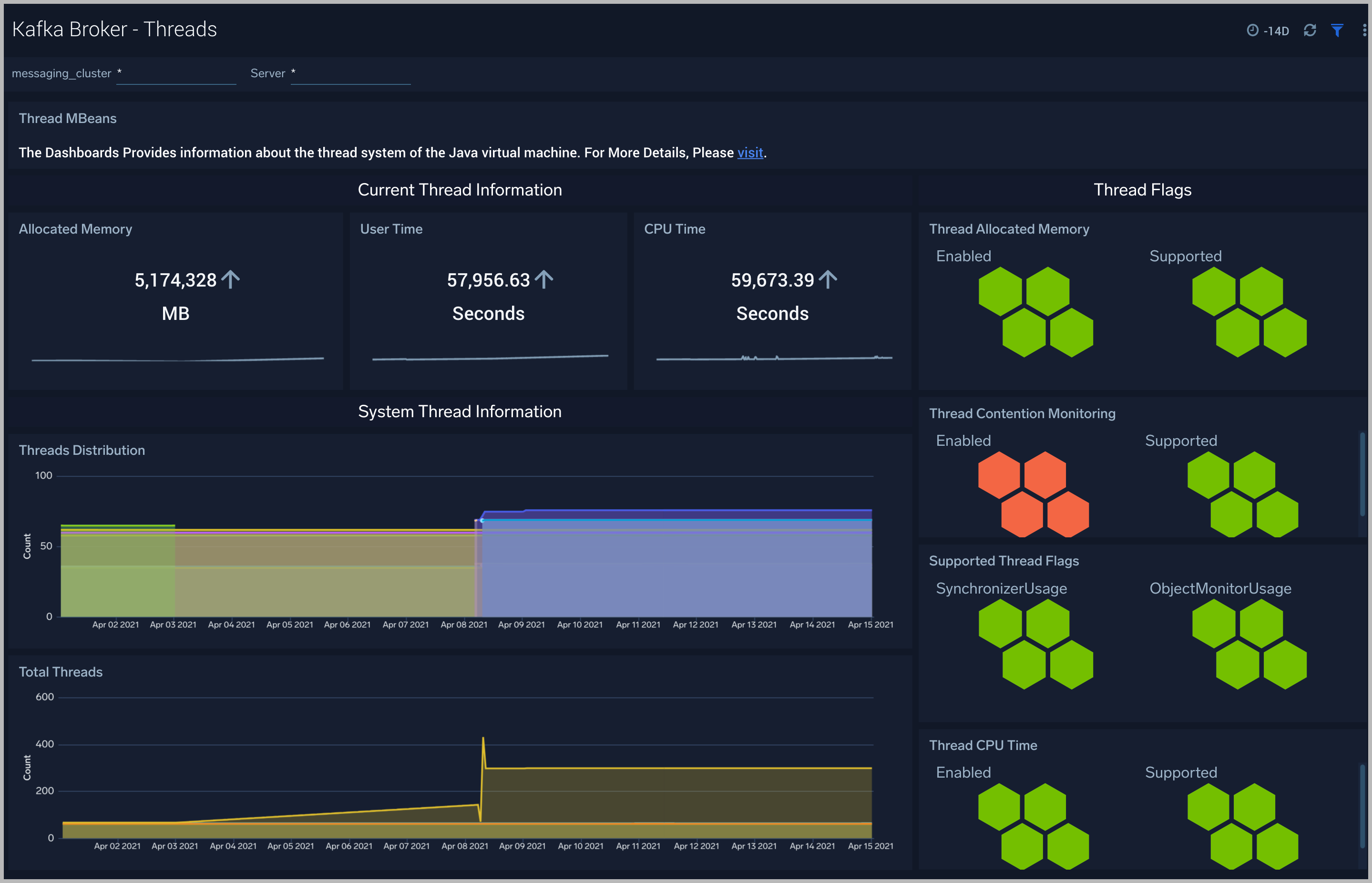
Kafka Broker - Threads
The Kafka Broker - Threads dashboard shows the key insights into the usage and type of threads created in your Kafka broker JVM
Use this dashboard to:
- Understand the dynamic behavior of the system using peak, daemon, and current threads.
- Gain insights into the memory and CPU time of the last executed thread.
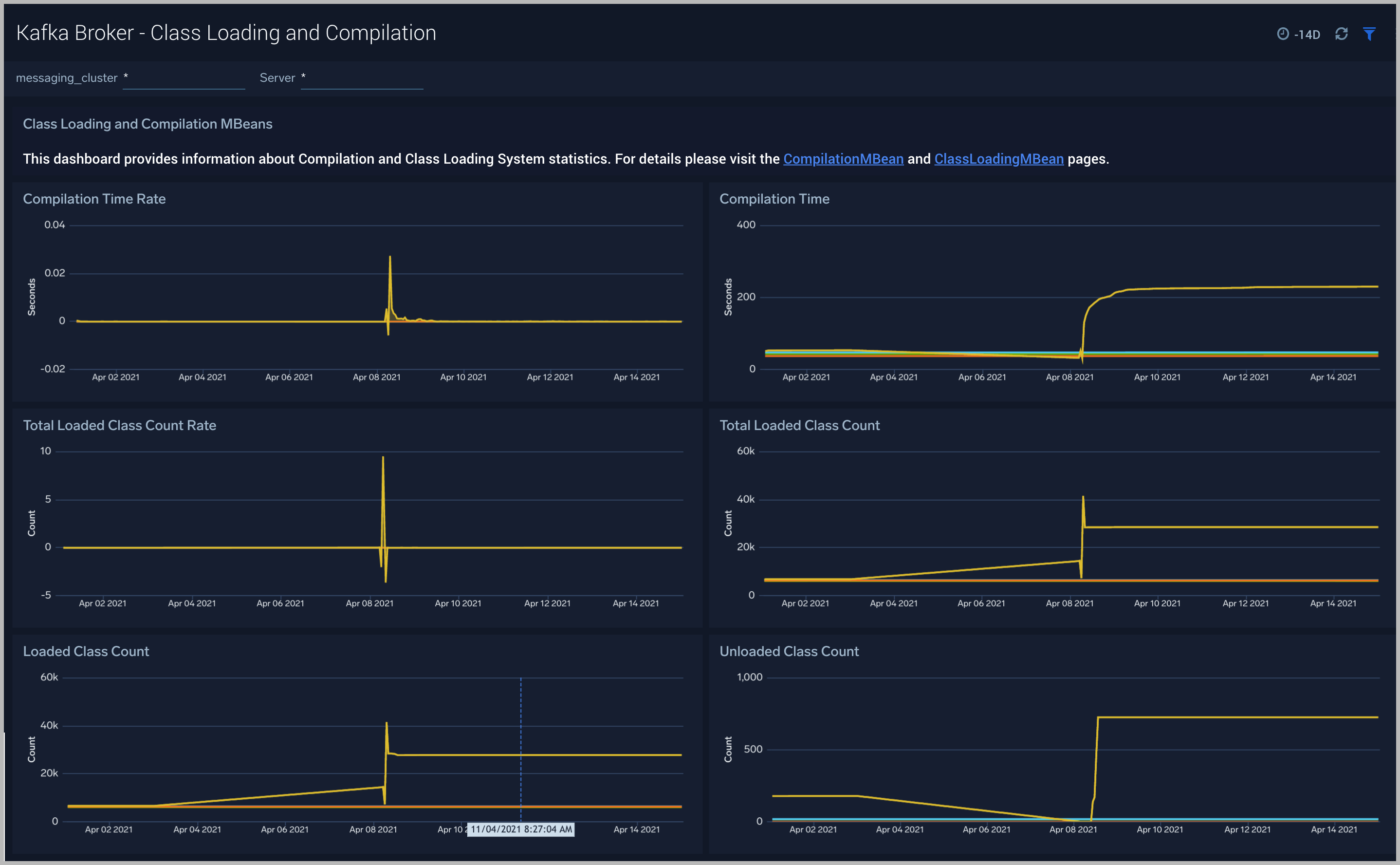
Kafka Broker - Class Loading and Compilation
The Kafka Broker - Class Loading and Compilation dashboard helps you get insights into the behavior of class count trends.
Use this dashboard to:
- Determine If the class count keeps increasing, this indicates that the same classes are loaded by multiple classloaders.
- Get insights into time spent by Java Virtual machines during compilation.
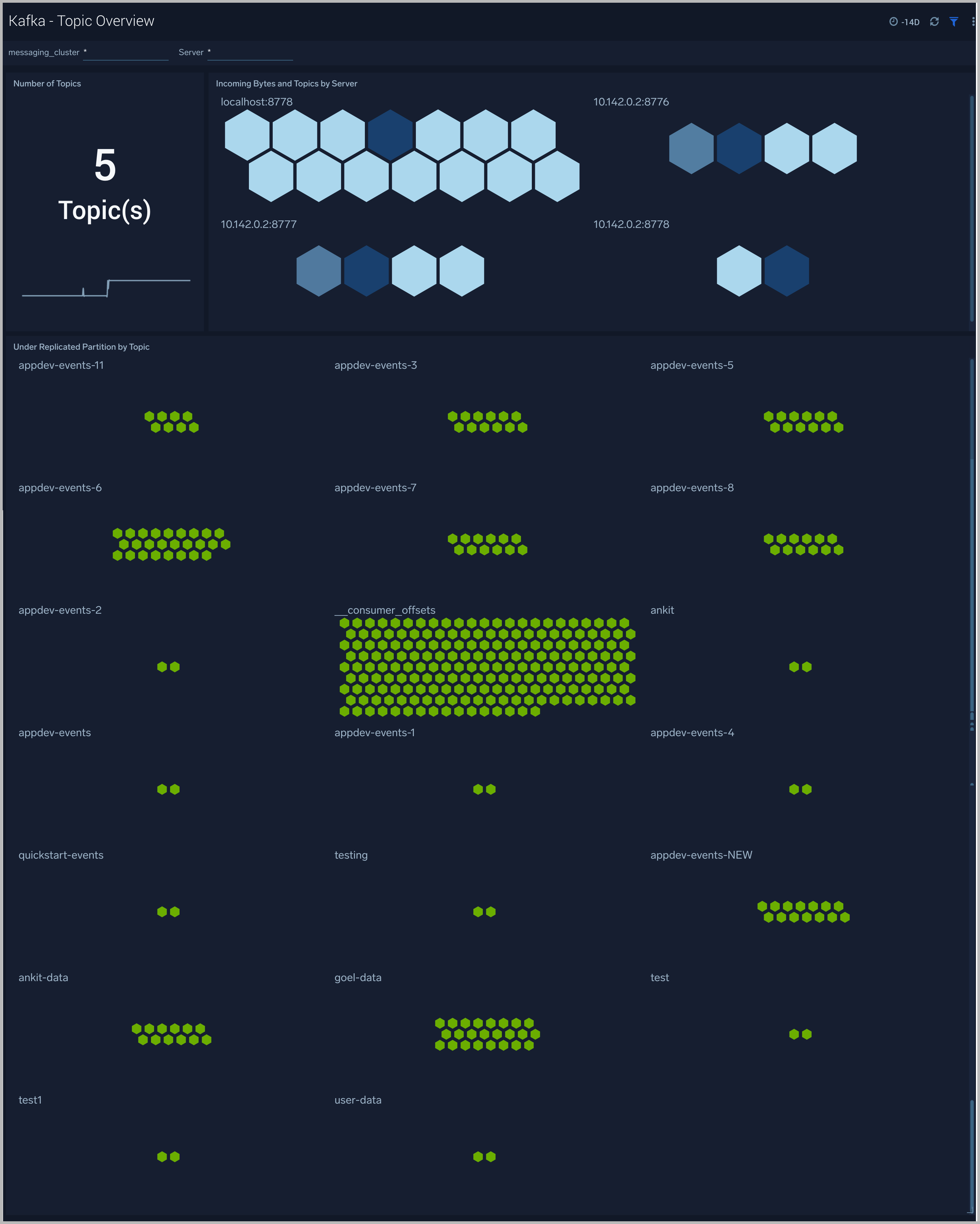
Kafka - Topic Overview
The Kafka - Topic Overview dashboard helps you quickly identify under-replicated partitions, and incoming bytes by Kafka topic, server and cluster.
Use this dashboard to:
-
Monitor under replicated partitions - The Under Replicated Partitions metric displays the number of partitions that do not have enough replicas to meet the desired replication factor. A partition will also be considered under-replicated if the correct number of replicas exist, but one or more of the replicas have fallen significantly behind the partition leader. The two most common causes of under-replicated partitions are that one or more brokers are unresponsive, or the cluster is experiencing performance issues and one or more brokers have fallen behind.
This metric is tagged with cluster, server, and topic info for easy troubleshooting. The colors in the Honeycomb chart are coded as follows:
- Green indicates there are no under Replicated Partitions.
- Red indicates a given partition is under replicated.
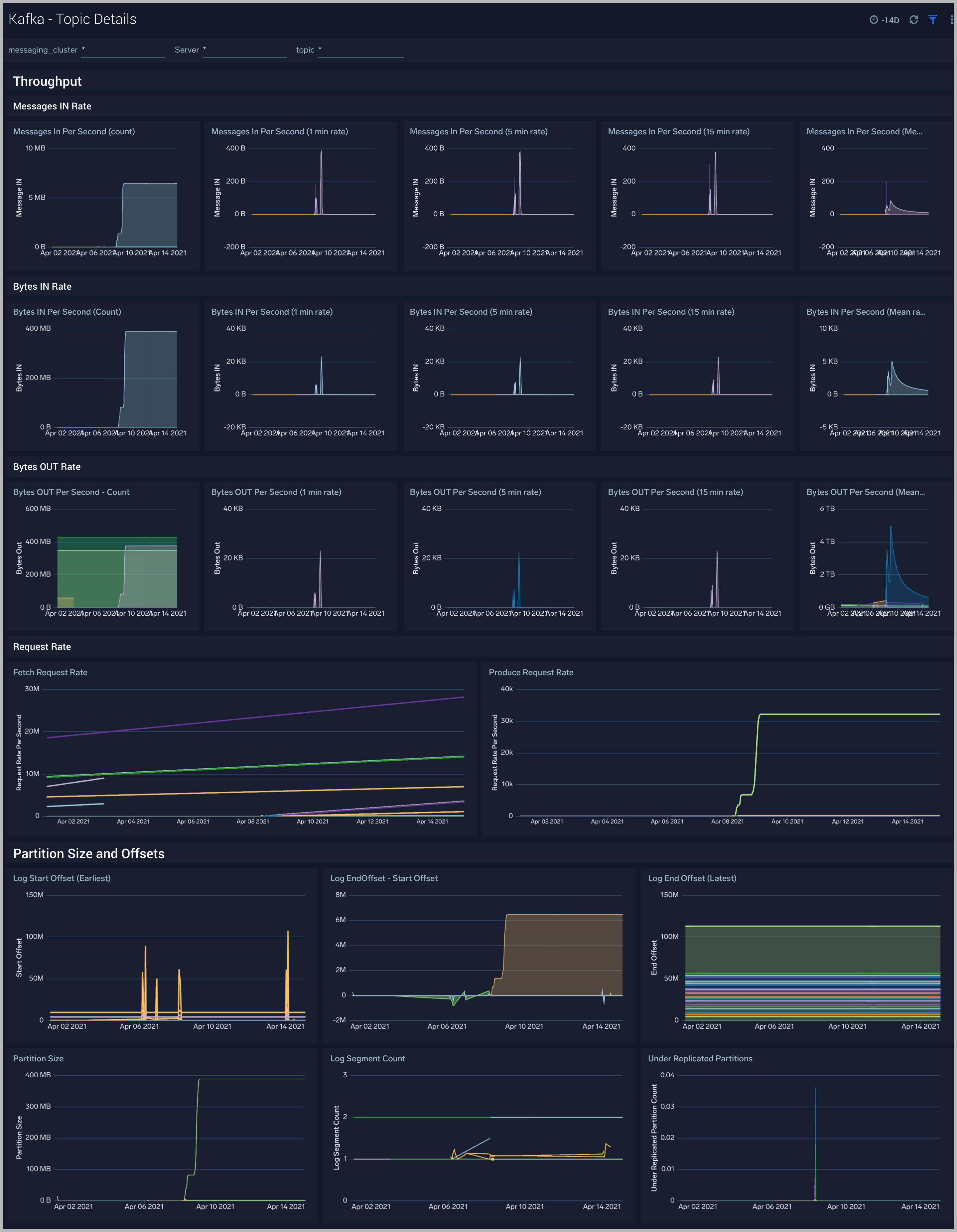
Kafka - Topic Details
The Kafka - Topic Details dashboard gives you insight into throughput, partition sizes and offsets across Kafka brokers, topics and clusters.
Use this dashboard to:
- Monitor metrics like Log partition size, log start offset, and log segment count metrics.
- Identify offline/under replicated partitions count. Partitions can be in this state on account of resource shortages or broker unavailability.
- Monitor the In Sync replica (ISR) Shrink rate. ISR shrinks occur when an in-sync broker goes down, as it decreases the number of in-sync replicas available for each partition replica on that broker.
- Monitor In Sync replica (ISR) Expand rate. ISR expansions occur when a broker comes online, such as when recovering from a failure or adding a new node. This increases the number of in-sync replicas available for each partition on that broker.
Create monitors for Kafka app
From your App Catalog:
- From the Sumo Logic navigation, select App Catalog.
- In the Search Apps field, search for and then select your app.
- Make sure the app is installed.
- Navigate to What's Included tab and scroll down to the Monitors section.
- Click Create next to the pre-configured monitors. In the create monitors window, adjust the trigger conditions and notifications settings based on your requirements.
- Scroll down to Monitor Details.
- Under Location click on New Folder.
note
By default, monitor will be saved in the root folder. So to make the maintenance easier, create a new folder in the location of your choice.
- Enter Folder Name. Folder Description is optional.
tip
Using app version in the folder name will be helpful to determine the versioning for future updates.
- Click Create. Once the folder is created, click on Save.
Kafka alerts
| Alert Name | Alert Description and conditions | Alert Condition | Recover Condition |
|---|---|---|---|
| Kafka - High Broker Disk Utilization | This alert fires when we detect that a disk on a broker node is more than 85% full. | >=85 | < 85 |
| Kafka - Failed Zookeeper connections | This alert fires when we detect Broker to Zookeeper connection failures. | ||
| Kafka - High Leader election rate | This alert fires when we detect high leader election rate. | ||
| Kafka - Garbage collection | This alert fires when we detect that the average Garbage Collection time on a given Kafka broker node over a 5 minute interval is more than one second. | > = 1 | < 1 |
| Kafka - Offline Partitions | This alert fires when we detect offline partitions on a given Kafka broker. | ||
| Kafka - Fatal Event on Broker | This alert fires when we detect a fatal operation on a Kafka broker node | >=1 | <1 |
| Kafka - Underreplicated Partitions | This alert fires when we detect underreplicated partitions on a given Kafka broker. | ||
| Kafka - Large number of broker errors | This alert fires when we detect that there are 5 or more errors on a Broker node within a time interval of 5 minutes. | ||
| Kafka - High CPU on Broker node | This alert fires when we detect that the average CPU utilization for a broker node is high (>=85%) for an interval of 5 minutes. | ||
| Kafka - Out of Sync Followers | This alert fires when we detect that there are Out of Sync Followers within a time interval of 5 minutes. | ||
| Kafka - High Broker Memory Utilization | This alert fires when the average memory utilization within a 5 minute interval for a given Kafka node is high (>=85%). | >= 85 | < 85 |
Kafka Metrics
Here's a list of available Kafka metrics.
| Kafka Metrics List |
|---|
| kafka_broker_disk_free |
| kafka_broker_disk_inodes_total |
| kafka_broker_disk_inodes_used |
| kafka_broker_disk_total |
| kafka_broker_disk_used_percent |
| kafka_broker_diskio_io_time |
| kafka_broker_diskio_iops_in_progress |
| kafka_broker_diskio_merged_reads |
| kafka_broker_diskio_merged_writes |
| kafka_broker_diskio_read_bytes |
| kafka_broker_diskio_read_time |
| kafka_broker_diskio_reads |
| kafka_broker_diskio_weighted_io_time |
| kafka_broker_diskio_write_bytes |
| kafka_broker_diskio_write_time |
| kafka_broker_diskio_writes |
| kafka_controller_ActiveControllerCount_Value |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_50thPercentile |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_75thPercentile |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_98thPercentile |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_99thPercentile |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_Count |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_Max |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_Mean |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_Min |
| kafka_controller_AutoLeaderBalanceRateAndTimeMs_StdDev |
| kafka_controller_ControlledShutdownRateAndTimeMs_99thPercentile |
| kafka_controller_ControlledShutdownRateAndTimeMs_FiveMinuteRate |
| kafka_controller_ControlledShutdownRateAndTimeMs_Min |
| kafka_controller_ControllerChangeRateAndTimeMs_50thPercentile |
| kafka_controller_ControllerChangeRateAndTimeMs_75thPercentile |
| kafka_controller_ControllerChangeRateAndTimeMs_98thPercentile |
| kafka_controller_ControllerChangeRateAndTimeMs_99thPercentile |
| kafka_controller_ControllerChangeRateAndTimeMs_Max |
| kafka_controller_ControllerChangeRateAndTimeMs_MeanRate |
| kafka_controller_ControllerChangeRateAndTimeMs_StdDev |
| kafka_controller_ControllerShutdownRateAndTimeMs_50thPercentile |
| kafka_controller_ControllerShutdownRateAndTimeMs_75thPercentile |
| kafka_controller_ControllerShutdownRateAndTimeMs_99thPercentile |
| kafka_controller_ControllerShutdownRateAndTimeMs_Count |
| kafka_controller_ControllerShutdownRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_ControllerShutdownRateAndTimeMs_Min |
| kafka_controller_ControllerShutdownRateAndTimeMs_StdDev |
| kafka_controller_EventQueueSize_Value |
| kafka_controller_EventQueueTimeMs_95thPercentile |
| kafka_controller_EventQueueTimeMs_98thPercentile |
| kafka_controller_EventQueueTimeMs_999thPercentile |
| kafka_controller_EventQueueTimeMs_Min |
| kafka_controller_GlobalPartitionCount_Value |
| kafka_controller_GlobalTopicCount_Value |
| kafka_controller_IsrChangeRateAndTimeMs_50thPercentile |
| kafka_controller_IsrChangeRateAndTimeMs_75thPercentile |
| kafka_controller_IsrChangeRateAndTimeMs_95thPercentile |
| kafka_controller_IsrChangeRateAndTimeMs_98thPercentile |
| kafka_controller_IsrChangeRateAndTimeMs_99thPercentile |
| kafka_controller_IsrChangeRateAndTimeMs_Count |
| kafka_controller_IsrChangeRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_IsrChangeRateAndTimeMs_FiveMinuteRate |
| kafka_controller_LeaderAndIsrResponseReceivedRateAndTimeMs_75thPercentile |
| kafka_controller_LeaderAndIsrResponseReceivedRateAndTimeMs_95thPercentile |
| kafka_controller_LeaderAndIsrResponseReceivedRateAndTimeMs_FiveMinuteRate |
| kafka_controller_LeaderAndIsrResponseReceivedRateAndTimeMs_MeanRate |
| kafka_controller_LeaderAndIsrResponseReceivedRateAndTimeMs_Min |
| kafka_controller_LeaderAndIsrResponseReceivedRateAndTimeMs_OneMinuteRate |
| kafka_controller_LeaderElectionRateAndTimeMs_95thPercentile |
| kafka_controller_LeaderElectionRateAndTimeMs_999thPercentile |
| kafka_controller_LeaderElectionRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_LeaderElectionRateAndTimeMs_Max |
| kafka_controller_LeaderElectionRateAndTimeMs_Min |
| kafka_controller_ListPartitionReassignmentRateAndTimeMs_50thPercentile |
| kafka_controller_ListPartitionReassignmentRateAndTimeMs_95thPercentile |
| kafka_controller_ListPartitionReassignmentRateAndTimeMs_999thPercentile |
| kafka_controller_ListPartitionReassignmentRateAndTimeMs_Mean |
| kafka_controller_ListPartitionReassignmentRateAndTimeMs_Min |
| kafka_controller_ListPartitionReassignmentRateAndTimeMs_OneMinuteRate |
| kafka_controller_LogDirChangeRateAndTimeMs_75thPercentile |
| kafka_controller_LogDirChangeRateAndTimeMs_999thPercentile |
| kafka_controller_LogDirChangeRateAndTimeMs_99thPercentile |
| kafka_controller_LogDirChangeRateAndTimeMs_Count |
| kafka_controller_LogDirChangeRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_50thPercentile |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_75thPercentile |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_98thPercentile |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_999thPercentile |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_FiveMinuteRate |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_Mean |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_Min |
| kafka_controller_ManualLeaderBalanceRateAndTimeMs_OneMinuteRate |
| kafka_controller_PartitionReassignmentRateAndTimeMs_50thPercentile |
| kafka_controller_PartitionReassignmentRateAndTimeMs_75thPercentile |
| kafka_controller_PartitionReassignmentRateAndTimeMs_98thPercentile |
| kafka_controller_PartitionReassignmentRateAndTimeMs_999thPercentile |
| kafka_controller_PartitionReassignmentRateAndTimeMs_99thPercentile |
| kafka_controller_PartitionReassignmentRateAndTimeMs_Count |
| kafka_controller_PartitionReassignmentRateAndTimeMs_FiveMinuteRate |
| kafka_controller_PartitionReassignmentRateAndTimeMs_Max |
| kafka_controller_PartitionReassignmentRateAndTimeMs_Mean |
| kafka_controller_PartitionReassignmentRateAndTimeMs_MeanRate |
| kafka_controller_PartitionReassignmentRateAndTimeMs_OneMinuteRate |
| kafka_controller_PreferredReplicaImbalanceCount_Value |
| kafka_controller_ReplicasIneligibleToDeleteCount_Value |
| kafka_controller_TopicChangeRateAndTimeMs_99thPercentile |
| kafka_controller_TopicChangeRateAndTimeMs_Count |
| kafka_controller_TopicChangeRateAndTimeMs_FiveMinuteRate |
| kafka_controller_TopicChangeRateAndTimeMs_Mean |
| kafka_controller_TopicChangeRateAndTimeMs_MeanRate |
| kafka_controller_TopicChangeRateAndTimeMs_Min |
| kafka_controller_TopicChangeRateAndTimeMs_StdDev |
| kafka_controller_TopicDeletionRateAndTimeMs_75thPercentile |
| kafka_controller_TopicDeletionRateAndTimeMs_95thPercentile |
| kafka_controller_TopicDeletionRateAndTimeMs_98thPercentile |
| kafka_controller_TopicDeletionRateAndTimeMs_Count |
| kafka_controller_TopicDeletionRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_TopicDeletionRateAndTimeMs_Max |
| kafka_controller_TopicDeletionRateAndTimeMs_OneMinuteRate |
| kafka_controller_TopicsToDeleteCount_Value |
| kafka_controller_TopicUncleanLeaderElectionEnableRateAndTimeMs_98thPercentile |
| kafka_controller_TopicUncleanLeaderElectionEnableRateAndTimeMs_999thPercentile |
| kafka_controller_TopicUncleanLeaderElectionEnableRateAndTimeMs_Count |
| kafka_controller_TopicUncleanLeaderElectionEnableRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_TotalQueueSize_Value |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_50thPercentile |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_75thPercentile |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_95thPercentile |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_98thPercentile |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_Count |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_FifteenMinuteRate |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_FiveMinuteRate |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_MeanRate |
| kafka_controller_UncleanLeaderElectionEnableRateAndTimeMs_Min |
| kafka_controller_UncleanLeaderElectionsPerSec_FifteenMinuteRate |
| kafka_controller_UpdateFeaturesRateAndTimeMs_MeanRate |
| kafka_controller_UpdateFeaturesRateAndTimeMs_StdDev |
| kafka_java_lang_GarbageCollector_CollectionCount |
| kafka_java_lang_GarbageCollector_CollectionTime |
| kafka_java_lang_GarbageCollector_LastGcInfo_endTime |
| kafka_java_lang_GarbageCollector_LastGcInfo_GcThreadCount |
| kafka_java_lang_GarbageCollector_LastGcInfo_id |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_Code_Cache_max |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_Code_Cache_used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_CodeHeap__non_nmethods__init |
kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_CodeHeap__non_profiled_nmethods__used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_Compressed_Class_Space_init |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Eden_Space_committed |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Eden_Space_init |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Eden_Space_max |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Old_Gen_committed |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Old_Gen_used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Survivor_Space_init |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageAfterGc_G1_Survivor_Space_used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_Code_Cache_init |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_Code_Cache_max |
kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_CodeHeap__non_nmethods__committed |
kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_CodeHeap__profiled_nmethods__used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_Compressed_Class_Space_used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Eden_Space_committed |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Eden_Space_init |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Eden_Space_max |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Old_Gen_committed |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Old_Gen_init |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Old_Gen_used |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_G1_Survivor_Space_max |
| kafka_java_lang_GarbageCollector_LastGcInfo_memoryUsageBeforeGc_Metaspace_used |
| kafka_java_lang_GarbageCollector_LastGcInfo_startTime |
| kafka_java_lang_Memory_HeapMemoryUsage_committed |
| kafka_java_lang_Memory_HeapMemoryUsage_init |
| kafka_java_lang_Memory_HeapMemoryUsage_used |
| kafka_java_lang_MemoryPool_CollectionUsage_committed |
| kafka_java_lang_MemoryPool_CollectionUsage_init |
| kafka_java_lang_MemoryPool_CollectionUsage_max |
| kafka_java_lang_MemoryPool_CollectionUsage_used |
| kafka_java_lang_MemoryPool_CollectionUsageThresholdSupported |
| kafka_java_lang_MemoryPool_PeakUsage_committed |
| kafka_java_lang_MemoryPool_PeakUsage_init |
| kafka_java_lang_MemoryPool_PeakUsage_max |
| kafka_java_lang_MemoryPool_PeakUsage_used |
| kafka_java_lang_MemoryPool_Usage_committed |
| kafka_java_lang_MemoryPool_Usage_init |
| kafka_java_lang_MemoryPool_Usage_max |
| kafka_java_lang_MemoryPool_Usage_used |
| kafka_java_lang_MemoryPool_UsageThresholdSupported |
| kafka_java_lang_OperatingSystem_CommittedVirtualMemorySize |
| kafka_java_lang_OperatingSystem_FreePhysicalMemorySize |
| kafka_java_lang_OperatingSystem_MaxFileDescriptorCount |
| kafka_java_lang_OperatingSystem_ProcessCpuTime |
| kafka_java_lang_OperatingSystem_TotalSwapSpaceSize |
| kafka_java_lang_Runtime_BootClassPathSupported |
| kafka_java_lang_Threading_CurrentThreadCpuTime |
| kafka_java_lang_Threading_SynchronizerUsageSupported |
| kafka_java_lang_Threading_ThreadAllocatedMemoryEnabled |
| kafka_java_lang_Threading_ThreadAllocatedMemorySupported |
| kafka_java_lang_Threading_ThreadCpuTimeEnabled |
| kafka_network_ResponseQueueSizeValue |
| kafka_partition_LogEndOffset |
| kafka_partition_LogStartOffset |
| kafka_partition_NumLogSegments |
| kafka_partition_Size |
| kafka_partition_UnderReplicatedPartitions |
| kafka_purgatory_Heartbeat_NumDelayedOperations |
| kafka_purgatory_Produce_NumDelayedOperations |
| kafka_purgatory_Produce_PurgatorySize |
| kafka_purgatory_Rebalance_NumDelayedOperations |
| kafka_purgatory_topic_NumDelayedOperations |
| kafka_purgatory_topic_PurgatorySize |
| kafka_replica_manager_FailedIsrUpdatesPerSec_Count |
| kafka_replica_manager_FailedIsrUpdatesPerSec_MeanRate |
| kafka_replica_manager_FailedIsrUpdatesPerSec_OneMinuteRate |
| kafka_replica_manager_IsrExpandsPerSec_FifteenMinuteRate |
| kafka_replica_manager_IsrExpandsPerSec_FiveMinuteRate |
| kafka_replica_manager_IsrExpandsPerSec_MeanRate |
| kafka_replica_manager_IsrShrinksPerSec_MeanRate |
| kafka_replica_manager_LeaderCount_Value |
| kafka_replica_manager_PartitionCount_Value |
| kafka_replica_manager_ReassigningPartitions_Value |
| kafka_replica_manager_UnderMinIsrPartitionCount_Value |
| kafka_replica_manager_UnderReplicatedPartitions_Value |
| kafka_request_handlers_MeanRate |
| kafka_request_LocalTimeMs_50thPercentile |
| kafka_request_LocalTimeMs_75thPercentile |
| kafka_request_LocalTimeMs_95thPercentile |
| kafka_request_LocalTimeMs_98thPercentile |
| kafka_request_LocalTimeMs_999thPercentile |
| kafka_request_LocalTimeMs_99thPercentile |
| kafka_request_LocalTimeMs_Count |
| kafka_request_LocalTimeMs_Max |
| kafka_request_LocalTimeMs_Mean |
| kafka_request_LocalTimeMs_Min |
| kafka_request_LocalTimeMs_StdDev |
| kafka_request_MessageConversionsTimeMs_50thPercentile |
| kafka_request_MessageConversionsTimeMs_75thPercentile |
| kafka_request_MessageConversionsTimeMs_95thPercentile |
| kafka_request_MessageConversionsTimeMs_98thPercentile |
| kafka_request_MessageConversionsTimeMs_99thPercentile |
| kafka_request_MessageConversionsTimeMs_Count |
| kafka_request_MessageConversionsTimeMs_Max |
| kafka_request_MessageConversionsTimeMs_Min |
| kafka_request_RemoteTimeMs_50thPercentile |
| kafka_request_RemoteTimeMs_75thPercentile |
| kafka_request_RemoteTimeMs_95thPercentile |
| kafka_request_RemoteTimeMs_98thPercentile |
| kafka_request_RemoteTimeMs_999thPercentile |
| kafka_request_RemoteTimeMs_99thPercentile |
| kafka_request_RemoteTimeMs_Count |
| kafka_request_RemoteTimeMs_Max |
| kafka_request_RemoteTimeMs_Mean |
| kafka_request_RemoteTimeMs_Min |
| kafka_request_RemoteTimeMs_StdDev |
| kafka_request_RequestBytes_50thPercentile |
| kafka_request_RequestBytes_75thPercentile |
| kafka_request_RequestBytes_95thPercentile |
| kafka_request_RequestBytes_98thPercentile |
| kafka_request_RequestBytes_999thPercentile |
| kafka_request_RequestBytes_99thPercentile |
| kafka_request_RequestBytes_Count |
| kafka_request_RequestBytes_Max |
| kafka_request_RequestBytes_Mean |
| kafka_request_RequestBytes_Min |
| kafka_request_RequestBytes_StdDev |
| kafka_request_RequestQueueTimeMs_50thPercentile |
| kafka_request_RequestQueueTimeMs_75thPercentile |
| kafka_request_RequestQueueTimeMs_95thPercentile |
| kafka_request_RequestQueueTimeMs_98thPercentile |
| kafka_request_RequestQueueTimeMs_999thPercentile |
| kafka_request_RequestQueueTimeMs_99thPercentile |
| kafka_request_RequestQueueTimeMs_Count |
| kafka_request_RequestQueueTimeMs_Max |
| kafka_request_RequestQueueTimeMs_Mean |
| kafka_request_RequestQueueTimeMs_Min |
| kafka_request_RequestQueueTimeMs_StdDev |
| kafka_request_ResponseQueueTimeMs_50thPercentile |
| kafka_request_ResponseQueueTimeMs_75thPercentile |
| kafka_request_ResponseQueueTimeMs_95thPercentile |
| kafka_request_ResponseQueueTimeMs_98thPercentile |
| kafka_request_ResponseQueueTimeMs_999thPercentile |
| kafka_request_ResponseQueueTimeMs_99thPercentile |
| kafka_request_ResponseQueueTimeMs_Count |
| kafka_request_ResponseQueueTimeMs_Max |
| kafka_request_ResponseQueueTimeMs_Mean |
| kafka_request_ResponseQueueTimeMs_Min |
| kafka_request_ResponseQueueTimeMs_StdDev |
| kafka_request_ResponseSendTimeMs_50thPercentile |
| kafka_request_ResponseSendTimeMs_75thPercentile |
| kafka_request_ResponseSendTimeMs_95thPercentile |
| kafka_request_ResponseSendTimeMs_98thPercentile |
| kafka_request_ResponseSendTimeMs_999thPercentile |
| kafka_request_ResponseSendTimeMs_99thPercentile |
| kafka_request_ResponseSendTimeMs_Count |
| kafka_request_ResponseSendTimeMs_Max |
| kafka_request_ResponseSendTimeMs_Mean |
| kafka_request_ResponseSendTimeMs_Min |
| kafka_request_ResponseSendTimeMs_StdDev |
| kafka_request_TemporaryMemoryBytes_75thPercentile |
| kafka_request_TemporaryMemoryBytes_98thPercentile |
| kafka_request_TemporaryMemoryBytes_999thPercentile |
| kafka_request_TemporaryMemoryBytes_99thPercentile |
| kafka_request_TemporaryMemoryBytes_Max |
| kafka_request_TemporaryMemoryBytes_Mean |
| kafka_request_TemporaryMemoryBytes_Min |
| kafka_request_TemporaryMemoryBytes_StdDev |
| kafka_request_ThrottleTimeMs_50thPercentile |
| kafka_request_ThrottleTimeMs_75thPercentile |
| kafka_request_ThrottleTimeMs_95thPercentile |
| kafka_request_ThrottleTimeMs_98thPercentile |
| kafka_request_ThrottleTimeMs_999thPercentile |
| kafka_request_ThrottleTimeMs_99thPercentile |
| kafka_request_ThrottleTimeMs_Count |
| kafka_request_ThrottleTimeMs_Max |
| kafka_request_ThrottleTimeMs_Mean |
| kafka_request_ThrottleTimeMs_Min |
| kafka_request_ThrottleTimeMs_StdDev |
| kafka_request_TotalTimeMs_50thPercentile |
| kafka_request_TotalTimeMs_75thPercentile |
| kafka_request_TotalTimeMs_95thPercentile |
| kafka_request_TotalTimeMs_98thPercentile |
| kafka_request_TotalTimeMs_999thPercentile |
| kafka_request_TotalTimeMs_99thPercentile |
| kafka_request_TotalTimeMs_Count |
| kafka_request_TotalTimeMs_Max |
| kafka_request_TotalTimeMs_Mean |
| kafka_request_TotalTimeMs_Min |
| kafka_request_TotalTimeMs_StdDev |
| kafka_topic_BytesInPerSec_Count |
| kafka_topic_BytesInPerSec_FiveMinuteRate |
| kafka_topic_BytesInPerSec_MeanRate |
| kafka_topic_BytesInPerSec_OneMinuteRate |
| kafka_topic_BytesOutPerSec_FiveMinuteRate |
| kafka_topic_BytesOutPerSec_MeanRate |
| kafka_topic_MessagesInPerSec_Count |
| kafka_topic_TotalFetchRequestsPerSec_FifteenMinuteRate |
| kafka_topic_TotalFetchRequestsPerSec_FiveMinuteRate |
| kafka_topic_TotalFetchRequestsPerSec_MeanRate |
| kafka_topic_TotalFetchRequestsPerSec_OneMinuteRate |
| kafka_topic_TotalProduceRequestsPerSec_Count |
| kafka_topic_TotalProduceRequestsPerSec_FifteenMinuteRate |
| kafka_topic_TotalProduceRequestsPerSec_FiveMinuteRate |
| kafka_topic_TotalProduceRequestsPerSec_MeanRate |
| kafka_topics_BytesInPerSec_Count |
| kafka_topics_BytesInPerSec_FifteenMinuteRate |
| kafka_topics_BytesInPerSec_MeanRate |
| kafka_topics_BytesInPerSec_OneMinuteRate |
| kafka_topics_BytesOutPerSec_MeanRate |
| kafka_topics_BytesOutPerSec_OneMinuteRate |
| kafka_topics_BytesRejectedPerSec_Count |
| kafka_topics_BytesRejectedPerSec_FiveMinuteRate |
| kafka_topics_BytesRejectedPerSec_MeanRate |
| kafka_topics_FailedFetchRequestsPerSec_MeanRate |
| kafka_topics_FailedProduceRequestsPerSec_FifteenMinuteRate |
| kafka_topics_FailedProduceRequestsPerSec_FiveMinuteRate |
| kafka_topics_FailedProduceRequestsPerSec_MeanRate |
| kafka_topics_FailedProduceRequestsPerSec_OneMinuteRate |
| kafka_topics_InvalidMagicNumberRecordsPerSec_FifteenMinuteRate |
| kafka_topics_InvalidMagicNumberRecordsPerSec_FiveMinuteRate |
| kafka_topics_InvalidMagicNumberRecordsPerSec_MeanRate |
| kafka_topics_InvalidMessageCrcRecordsPerSec_FifteenMinuteRate |
| kafka_topics_InvalidOffsetOrSequenceRecordsPerSec_FiveMinuteRate |
| kafka_topics_InvalidOffsetOrSequenceRecordsPerSec_MeanRate |
| kafka_topics_InvalidOffsetOrSequenceRecordsPerSec_OneMinuteRate |
| kafka_topics_MessagesInPerSec_Count |
| kafka_topics_MessagesInPerSec_FifteenMinuteRate |
| kafka_topics_MessagesInPerSec_FiveMinuteRate |
| kafka_topics_NoKeyCompactedTopicRecordsPerSec_Count |
| kafka_topics_NoKeyCompactedTopicRecordsPerSec_FifteenMinuteRate |
| kafka_topics_NoKeyCompactedTopicRecordsPerSec_FiveMinuteRate |
| kafka_topics_NoKeyCompactedTopicRecordsPerSec_MeanRate |
| kafka_topics_ProduceMessageConversionsPerSec_FifteenMinuteRate |
| kafka_topics_ProduceMessageConversionsPerSec_OneMinuteRate |
| kafka_topics_ReassignmentBytesInPerSec_Count |
| kafka_topics_ReassignmentBytesInPerSec_FifteenMinuteRate |
| kafka_topics_ReassignmentBytesInPerSec_FiveMinuteRate |
| kafka_topics_ReassignmentBytesInPerSec_MeanRate |
| kafka_topics_ReassignmentBytesInPerSec_OneMinuteRate |
| kafka_topics_ReassignmentBytesOutPerSec_Count |
| kafka_topics_ReassignmentBytesOutPerSec_FifteenMinuteRate |
| kafka_topics_ReassignmentBytesOutPerSec_MeanRate |
| kafka_topics_ReassignmentBytesOutPerSec_OneMinuteRate |
| kafka_topics_ReplicationBytesInPerSec_Count |
| kafka_topics_ReplicationBytesInPerSec_MeanRate |
| kafka_topics_ReplicationBytesOutPerSec_Count |
| kafka_topics_ReplicationBytesOutPerSec_FiveMinuteRate |
| kafka_topics_ReplicationBytesOutPerSec_MeanRate |
| kafka_topics_ReplicationBytesOutPerSec_OneMinuteRate |
| kafka_topics_TotalFetchRequestsPerSec_Count |
| kafka_topics_TotalFetchRequestsPerSec_FifteenMinuteRate |
| kafka_topics_TotalFetchRequestsPerSec_FiveMinuteRate |
| kafka_topics_TotalFetchRequestsPerSec_MeanRate |
| kafka_topics_TotalProduceRequestsPerSec_FiveMinuteRate |
| kafka_topics_TotalProduceRequestsPerSec_MeanRate |
| kafka_topics_TotalProduceRequestsPerSec_OneMinuteRate |
| kafka_zookeeper_auth_failures_FifteenMinuteRate |
| kafka_zookeeper_auth_failures_FiveMinuteRate |
| kafka_zookeeper_authentications_Count |
| kafka_zookeeper_authentications_OneMinuteRate |
| kafka_zookeeper_disconnects_FiveMinuteRate |
| kafka_zookeeper_expires_FifteenMinuteRate |
| kafka_zookeeper_expires_FiveMinuteRate |
| kafka_zookeeper_expires_MeanRate |
| kafka_zookeeper_expires_OneMinuteRate |
| kafka_zookeeper_readonly_connects_FifteenMinuteRate |
| kafka_zookeeper_readonly_connects_MeanRate |
| kafka_zookeeper_sync_connects_FifteenMinuteRate |
| kafka_zookeeper_sync_connects_MeanRate |
| kafka_zookeeper_sync_connects_OneMinuteRate |