Flex Pricing FAQ
This page answers frequently asked questions about Flex pricing.
What is Flex Pricing?
Introducing Sumo Logic Flex: the solution that revolutionizes log analytics pricing for technical teams. Bid farewell to data tiers as we usher in an era where your insights and analytics volume, not data ingestion, dictates pricing. The value of log data is now in sync with the insights and analytics you generate from the data, not the data volume or management process.
With Sumo Logic Flex, you gain an efficient, centralized log analytics framework capable of managing enterprise-wide cloud-scale log ingestion without cost concerns. Consolidate all your data streams — application, infrastructure, security — into a single platform with unlimited user access, fostering seamless collaboration.
The more log data ingested, the sharper your analytics and ML/AI insights become. By eliminating ingest limitations and empowering an ML/AI-driven single source of truth for analytics, Flex enables DevOps and DevSecOps teams to troubleshoot faster, accelerate release velocity, and ensure reliable, secure digital experiences.
Is Flex Pricing available to existing Cloud Flex customers?
No, Flex Pricing is not currently available for existing Cloud Flex customers. However, it will become available in the near future. Currently, Flex Pricing is the default plan for new customers signing up with Sumo Logic.
How is Flex Pricing different from the other data tiers?
With Flex Pricing, there is no cost to ingest and index log data, and no requirement to manage storage on your own or rehydrate at a premium for log indexing. This removes the complexity of predetermining the type of analytics required before the data is in the system. You simply pay for analytics and insights, not data management.
Can I restrict access to Flex data to select users?
Yes, you can use Role-Based Access Control (RBAC) to restrict access to partitions in Flex. Although you can’t use a role search filter to restrict access to a partition by name, you can filter by the metadata that forms the routing expression for a partition.
For example, if you want to restrict access to a partition whose routing expression is:
_sourceCategory=staging/*
You can create a role with this role search filter:
!(_sourceCategory=staging/*)
Then, you assign that role to any user that shouldn’t have access to data in that partition.
How can I get visibility into our Flex search costs?
Your Account Overview page shows the credits your org has consumed for Flex data searches. 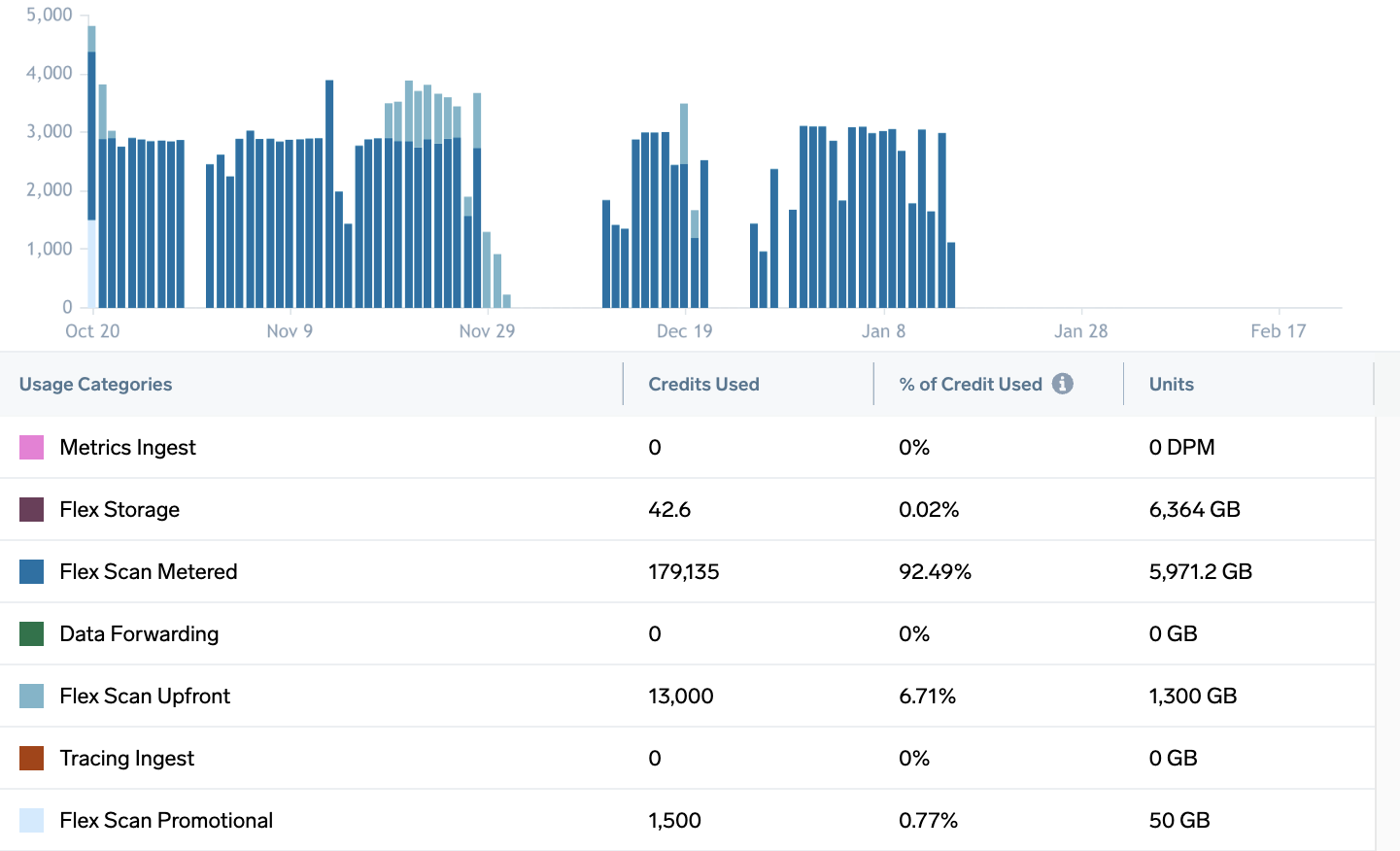
How can I optimize Flex data search costs?
Below are some ways to control the cost of running queries data in Flex:
- Logically apportion your data, depending on how you plan to query it, into multiple partitions, instead of creating a single large partition. Try to limit queries to a single partition as much as possible. Assume you have three different services sending logs to Sumo Logic. There a couple of approaches you can take:
- Create one partition per service. All the logs for that service go there. This approach can be leveraged if each team owns a service, and they typically query the logs within their service to find issues.
- Create one partition per log type (debug, infra, and so on). This approach can be leveraged if, most of the time, the team searches one log type per query. For example, the team only queries debug logs, and typically queries other logs like Database logs and OS logs in separate queries.
- Try to use a restrictive time range, instead of running a query with a very long time range.
- Use indexes with the metadata fields to narrow down the volume of data scanned. This in turn will help you to reduce the scan cost. For example, if you're querying data from the
k8s_hostsource and it's being sent to multiple partitions, you can limit the scope of your search to theabcpartition by using_index=abcfor the selected time range._index=abc AND _sourceCategory=k8s_host
Using keywords or other metadata in a query will not reduce the amount of data scanned. For example, the inclusion of a keyword and custom field in the scope of the query below does not reduce the amount of data that Sumo Logic will scan. Sumo Logic will scan all data in the partition named ybase_partition.
_index=ybase_partition (error and cluster=nxt)
The table below should give you a sense of how the number of partitions you use and the query time range affects the volume of data scanned.
| Query Time Range | Number of Partitions Queried | Data Scanned |
|---|---|---|
| 1 day | 1 | 2 TB |
| 1/2 day | 1 | 1 TB |
| 4 day | 1 | 8 TB |
| 1 day | 2 | 4 TB |
| 1/2 day | 2 | 2 TB |
| 2 days | 2 | 8 TB |
Given all partition definitions and the user's query, Sumo Logic automatically optimizes query execution by rewriting the query to include _view and _index clauses. The system then identifies the minimal list of views required to serve the query, which ultimately contributes to the scanned volume, whether actual or estimated.
What is an ideal size for a partition for Flex?
We recommend you configure partitions to have less than 5 TB per day flowing into them. This practice:
- Reduces the cost of each query.
- Accelerates queries, as less data has to be scanned.
How can I optimize my query using default scope?
Default scope allows you to include or exclude the partitions in the search query, helping you to optimize the search cost. For example, if a query needs to run through 10 partitions, which consumes about 10 GB of search data, narrowing the search query using the default scope can improve the query performance and reduce scan cost. You can modify the default scope by selecting or deselecting the Include this partition in default scope checkbox when creating/updating your partition. Let's say that out of 10 partitions, you excluded two partitions. Now, when you run a query that does not have _index / _view term referenced in the query, the search will only consider the included partitions, reducing the amount of data scanned and lowering the cost.
If you do not specify a partition name using _index or _view, or if you do not use metadata fields in your query scope that correspond to the routing expression of a partition, you will be billed for all default scope partitions that are not explicitly excluded. This also includes the sumologic_default partition.
When partitions are marked as included and _index or _view is not referenced in the query, all partitions part of default scope will be considered by default. Default scope is also useful when AND or OR conditions are used in the query with _index. For example, consider you have three partitions: Partition A (Excluded), Partition B (Included), and Partition C (Included). Below are some scenarios:
- When you run the query without referring to
_index, for exampleerror | count, only Partition B and Partition C will be considered for the query, as Partition A is excluded from the default scope. - When you run a query referring to an index term, for example
_index="Partition A", only Partition A will be considered for the query. - Similarly, when you refer to multiple index terms, for example
_index="Partition A" OR _index="Partition B", only Partition A and Partition B will be considered for the query. - However, when you run a query like
_index="Partition A" OR error, all partitions (Partition A, Partition B, and Partition C) will be considered. This is because theerrorkeyword might be present in Partition B or C as well, requiring a scan of all three partitions.
How are preview queries charged?
While the current impact is extremely minimal, preview queries that you run during scenarios like monitor creation may incur repetitive but negligible charges.
What happens to the queries with _dataTier modifier while migrating to Flex Pricing?
Users will continue to have support for the _dataTier modifier while still migrating to Flex pricing.
After migrating to the Flex pricing, queries with the _dataTier modifier will continue to work as usual. The definition of _dataTier=Continuous or Frequent or Infrequent at the time of transition is a snapshot of the partitions that were part of the tier. This ensures a smooth transition to Flex pricing without encountering any issues.
Once the move to Flex pricing is settled, based on the convenience of Administrators and Users, it is recommended to rewrite the queries to move away from the _dataTier modifier to improve the scope of queries. There is currently no set time to deprecate the support for the _dataTier modifier in Flex pricing.
Are audit index queries charged?
Queries to the following audit indexes are not charged:
sumologic_audit_eventssumologic_system_eventssumologic_search_usage_per_query