along Metrics Statement
The along metrics statement is useful when you join queries – it allows you to control what results are joined based on the value of one or more result fields. For more information, see Join Query Results.
Syntax
<expression> [along <field>[, <field>, …]]
Example
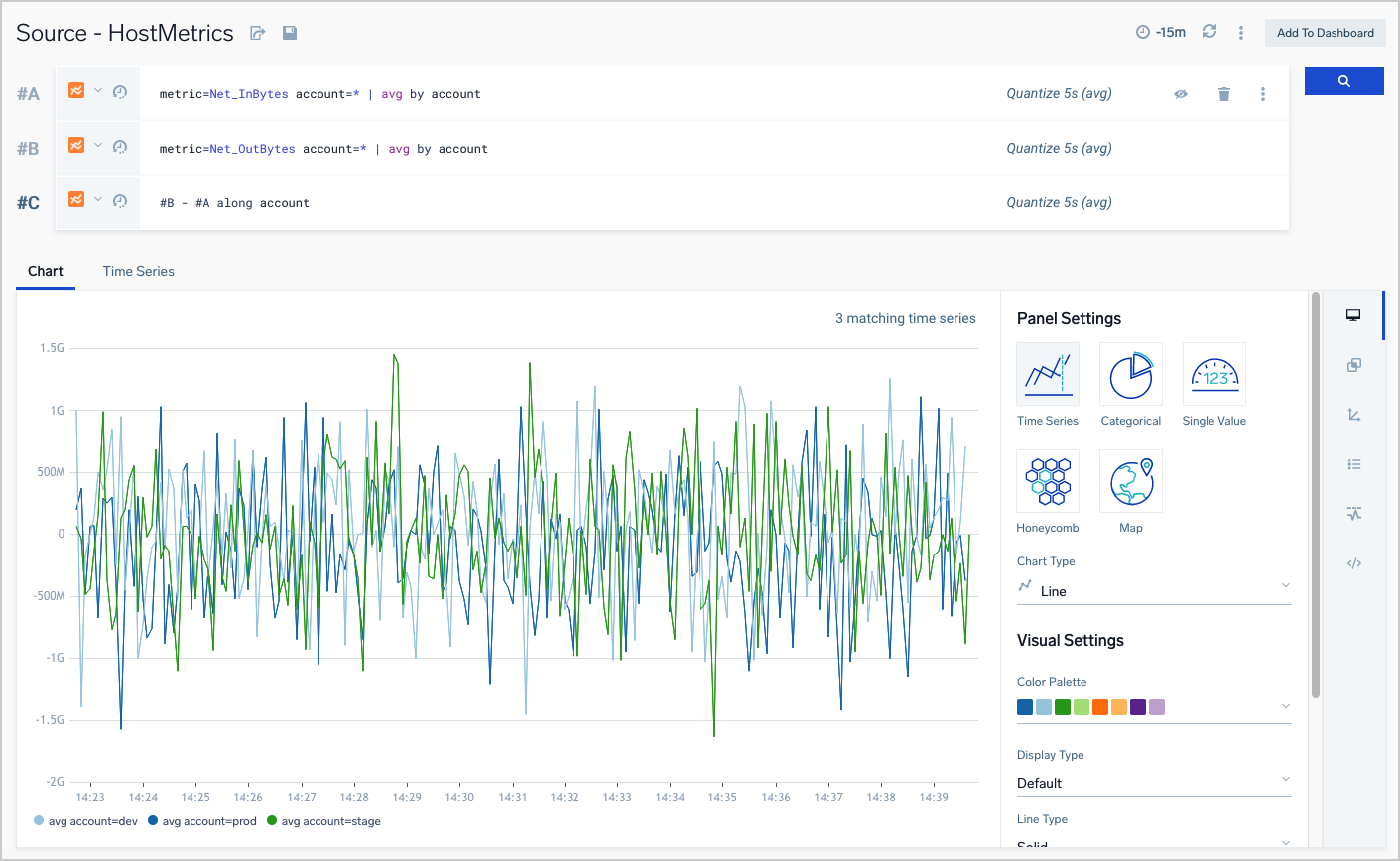
Queries #A and #B return the Net_InBytes and Net_OutBytes metrics with the assigned account and averaged over account. Query #C calculates the difference of the pairs of time series from #A and #B whose account value matches.
#A: metric=Net_InBytes account=* | avg by account
#B: metric=Net_OutBytes account=* | avg by account
#C: #B - #A along account