Optimize Your Search with Partitions
What is a Partition?
A partition stores your data in an index separate from the rest of your account's data so you can optimize searches, manage variable retention, and specify certain data to forward to S3 or GCS.
Partitions route your data to an index becoming a separate subset of data in your account. Creating smaller and separate subsets of data is central to search optimization. When you run a search against an index, results are returned more quickly and efficiently because the search runs against a smaller data set.
This example shows a customer that created three additional Partitions to separate data by environment.

Consider the following queries:
| Query | Partition Status | Path |
|---|---|---|
| Query 1 | _sourceCategory=prod/security/snort | |
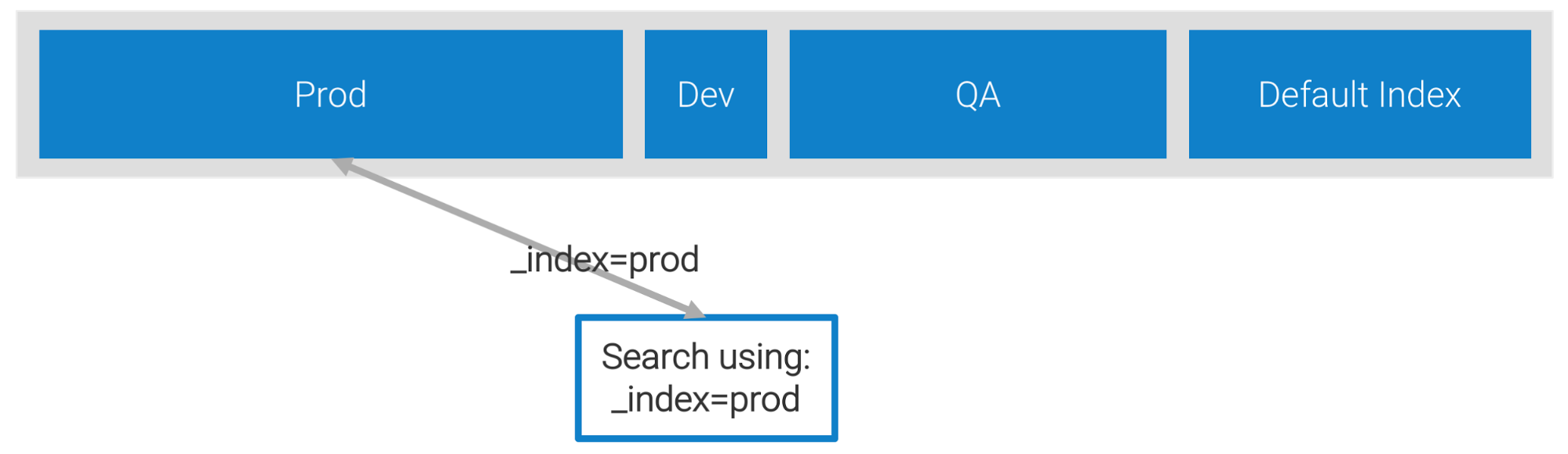
| Query 2 | Partitions in place | _index=prod AND _sourceCategory=prod/security/snort |
| Query 3 | Partitions in place | _sourceCategory=prod/security/snort |
| Query 4 | Partitions in place | _sourceCategory=stage/aws/cloudtrail OR _sourceCategory=prod/security/snort |
- Query 1. There are no custom Partitions created and you only have the Default Index, 100% of your data across all partitions is scanned in order to find all production log messages for the Snort security app.
- Query 2. Partitions do exist,
_index=prodlimits the scope of the query and only about 40% of the data is scanned to get the same results as Query 1. But it is redundant. - Query 3. You can take advantage of Partitions without having to rewrite your existing queries. Sumo Logic's behind-the-scenes Query Rewriting, performed for queries run against data, is smart enough to understand that the scope of what you are looking for is included within
_index=prod; therefore at runtime, it will rewrite the query as Query 2. - Query 4. We want to search for data that is in a custom Partition, as well as data that exists in the Default Index. However, query rewriting does not have the ability to OR indexes together. Instead, another behind-the-scenes feature, Inverse View Rewriting kicks in, we know that the data is NOT contained in the DEV and QA index, so those will be skipped. This query will only scan the Prod index and the Default Index.
You can create partitions within both data tier and flex plans.
Data Tier plans
You can use data tiers if you have a license for Sumo Logic's Enterprise Suite Credits account type. By default, all log data ingested into Sumo Logic is assigned to the sumologic_default partition, which operates on the Continuous tier. If you have an Enterprise Suite Credits account type, you have the option to assign some log data to either the Frequent or Infrequent tier by creating a separate partition with a specific routing expression and assigned data tier.
Different data tiers come with varying credit burn rates. Costs will be incurred for ingesting log data into Sumo Logic based on the tier: Continuous, Frequent, and Infrequent. Logs held in the Infrequent tier will also incur costs when the data is subsequently queried for analysis. The number of credits consumed will be determined by the volume of log data scanned. To learn more, refer to the Data Tier Partitions.
Flex plans
In contrast, it is recommended to opt for Sumo Logic's Flex account type to use the Flex plan, which does not involve assigning log data to specific tiers. All log data* ingested under a Flex plan is classified as Flex data, and pricing is determined on the volume of log data scanned when running interactive log searches, dashboards, monitors, and other content that generates log queries.
The creation of partitions is supported in Flex plans and it is a useful method for managing costs by controlling the amount of data scanned. Unlike data tier plans, partitions created in a Flex plan do not have different data tiers. Depending on the account type chosen within Flex, you may access additional features such as data forwarding, dashboards, monitors, scheduled searches, and scheduled views. To learn more about creating partitions with the Flex plan, refer to the Flex Partitions.
*Customers licensed for Enterprise Suite Flex can also license Cloud SIEM. With this, the subset of ingested log data forwarded to the Cloud SIEM solution is not categorized as Flex data. Instead of price being based on the volume of data scanned by queries, it is based on the volume of log data forwarded to Cloud SIEM.
What is Query Rewriting?
Whenever possible, we rewrite a user's queries to perform better. We'll illustrate this using a simple example below:.
This means that:
_sourceCategory=prod/security/snort
Will be rewritten as:
_index=prod AND _sourceCategory=prod/security/snort
This is possible because:
- The example environment is using a robust
_sourceCategorynaming convention - The Partition was scoped using
_sourceCategory - The searches are using
_sourceCategory, so they can easily be mapped to Partitions - The scope of this search (
_sourceCategory=prod/security/snort) falls within the scope of the Partition (_sourceCategory=prod/*)
Therefore, defining a broad scope for your Partitions (for example, _sourceCategory=prod/*), and searching with _sourceCategory allows you to take advantage of query rewriting, and it allows you to potentially not have to manually rewrite your existing queries.
We have used a simple example of non-overlapping partitions all defined on _sourceCategory. Your data organization needs may be more complex, and in those cases we try to do a best effort query re-writing.
Create a Partition
As an Admin, you create Partitions by specifying their routing expression. We recommend you use _sourceCategory to define your routing expressions to take full advantage of Query Rewriting.
The following example shows the routing expression for the three custom Partitions:
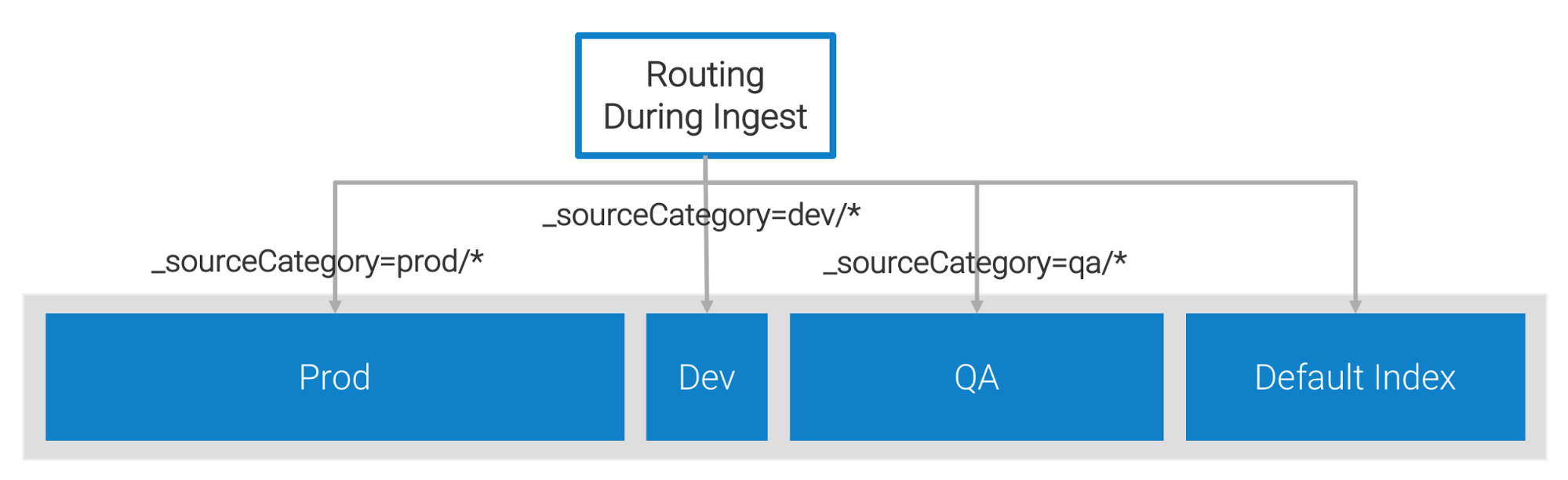
Here are simple steps to create a Partition named Dev:
- New UI. In the main Sumo Logic menu select Data Management, and then under Logs select Partitions. You can also click the Go To... menu at the top of the screen and select Partitions.
Classic UI. In the main Sumo Logic menu, select Manage Data > Logs > Partitions. - Click Add Partition.
- In the Name field, enter
Dev. - In the Routing Expression field enter
_sourceCategory=Dev. - Select Apply the retention period of sumologic_default.
- Click Save.
How can my team use Partitions?
Once created, Partitions can be used by anyone in your account, helping you reduce the scope of your searches and improve the performance for all users. Query 2 above takes advantage of our newly created Partition to scan only 40% of the data. As noted above, Query 3 is also a good option, because Query Rewriting will produce the same results as Query 1. This might eliminate the need to edit all your queries once your Partitions are in place.
Best Practices when using Partitions
Avoid creating too many partitions to avoid fragmentation
We recommend 20 as the maximum number of partitions. This is to avoid both index fragmentation and data management issues.
Optimal partitions are sized between 1% and 30% of total ingest
Partitions that are too small may cause index fragmentation and degraded search performance. It is possible to create partitions larger than 30% without adverse effects, however the performance gains will be diminished.
Don’t create overlapping partitions
This will lead to duplication of data (increasing your billed ingest rate), and degraded performance. Sumo Logic will not return duplicate results, but the process of de-duplication is time consuming and will increase query durations.
Do not use the NOT operator in partition definitions
This will likely exclude data that should be contained within your partition and will reduce the chances that your partition will be reused by queries that are rewritten.
Do not use sourceHost to define your partitions
It may prevent you from searching horizontally without OR’ing partitions together.
Use an intuitive naming scheme
This helps users easily identify the correct partition to use.
Keep your partition broadly scoped with _sourceCategory and avoid keywords
Use _sourceCategory in your partitions definitions and avoid keywords to keep your partition broadly scoped. You can always narrow down the scope of your search when you query your partition.
Group similar data together
In the example above, we used prod/QA/Dev environment, as you will most often be searching across all your Prod data. If you need to search across environments, you can OR 2 or more Partitions.
More information
See Manage Partitions.