Google BigQuery Source
Google Cloud’s BigQuery is a fully managed enterprise data warehouse that helps you to manage and analyze your data, which also provides built-in features such as ML, geospatial analysis, and business intelligence. The Google BigQuery integration gets data from a Google BigQuery table via a provided query.
Data collected
| Polling Interval | Data |
|---|---|
| 5 min | BigQuery API |
Setup
Make sure that you have BigQuery Data Viewer and BigQuery Job User permissions when creating the service account for the Big Query source.
Vendor configuration
Follow the below steps to get the Service Account's Credential JSON file to run BigQuery jobs:
- Open IAM & Admin under Google Cloud Console.
- Select the Service Account tab.
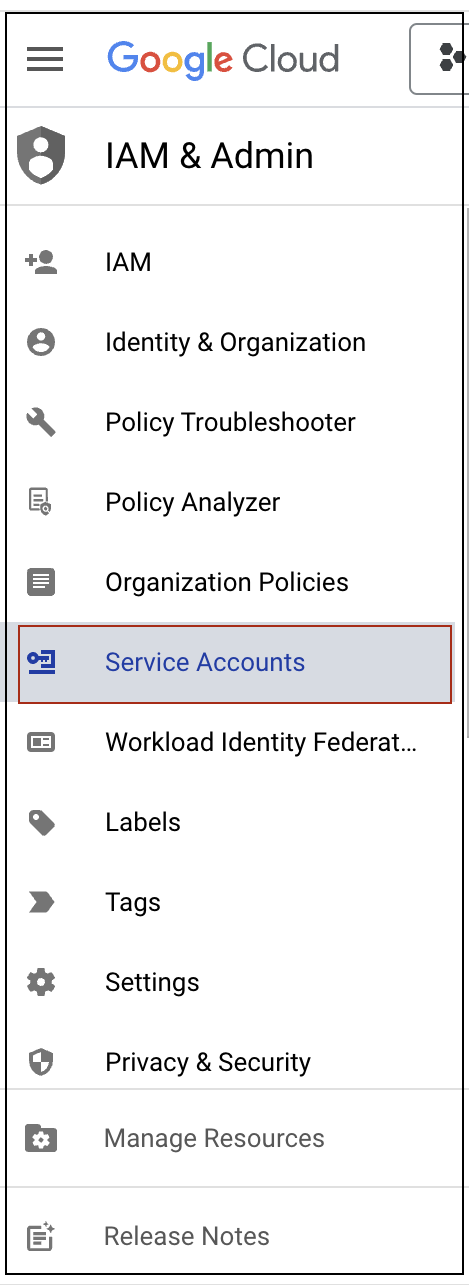
- From the project dropdown button, select the project where you will run the BigQuery jobs.

- Click on Create a Service Account and follow the instructions in Create service accounts google cloud docs.

- Click on the email address provisioned during the creation and then click the KEYS tab.
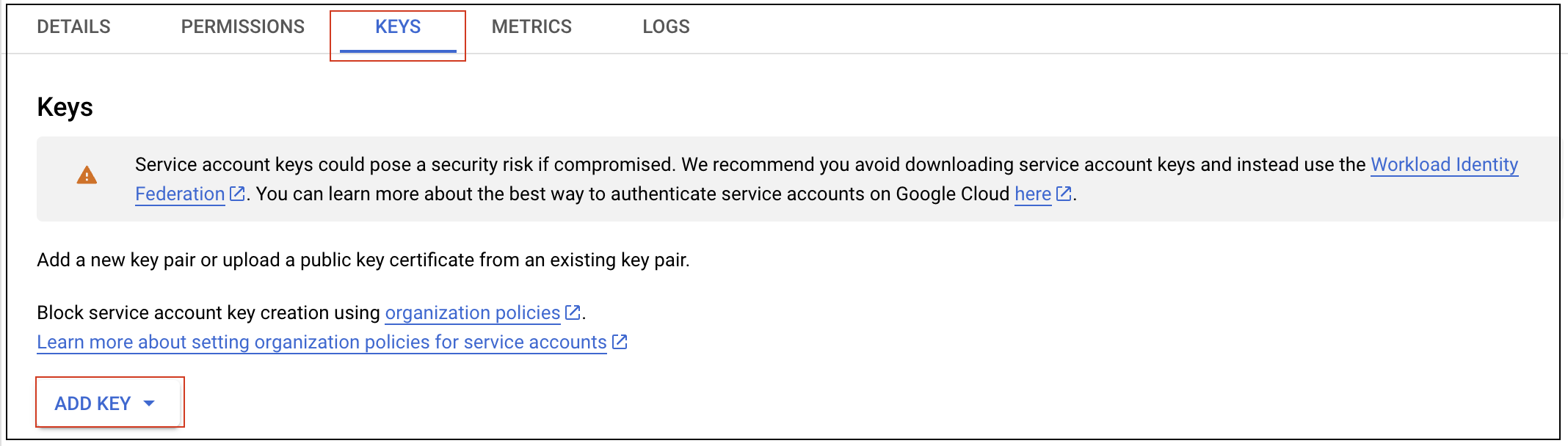
- Click ADD KEY and choose Create new key.
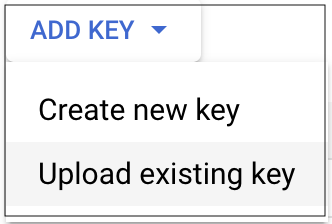
- Select key type as JSON.

- Click Create. A JSON key file is downloaded to your computer.
Source configuration
When you create an Google BigQuery Source, you add it to a Hosted Collector. Before creating the Source, identify the Hosted Collector you want to use or create a new Hosted Collector. For instructions, see Configure a Hosted Collector.
Before setting up the integration, test out the query with the checkpointing logic and a specific checkpoint value in the Google BigQuery console.
To configure an Google BigQuery Source:
- Classic UI. In the main Sumo Logic menu, select Manage Data > Collection > Collection.
New UI. In the Sumo Logic top menu select Configuration, and then under Data Collection select Collection. You can also click the Go To... menu at the top of the screen and select Collection. - On the Collection page, click Add Source next to a Hosted Collector.
- Search for and select Google BigQuery.
- Enter a Name for the Source. The description is optional.
- (Optional) For Source Category, enter any string to tag the output collected from the Source. Category metadata is stored in a searchable field called
_sourceCategory. - (Optional) Fields. Click the +Add button to define the fields you want to associate. Each field needs a name (key) and value.
 A green circle with a check mark is shown when the field exists in the Fields table schema.
A green circle with a check mark is shown when the field exists in the Fields table schema. An orange triangle with an exclamation point is shown when the field doesn't exist in the Fields table schema. In this case, an option to automatically add the nonexistent fields to the Fields table schema is provided. If a field is sent to Sumo Logic that does not exist in the Fields schema it is ignored, known as dropped.
An orange triangle with an exclamation point is shown when the field doesn't exist in the Fields table schema. In this case, an option to automatically add the nonexistent fields to the Fields table schema is provided. If a field is sent to Sumo Logic that does not exist in the Fields schema it is ignored, known as dropped.
- Project ID. Enter the unique identifier number for your BigQuery project. You can find this from the Google Cloud Console.
- Checkpoint Field. Enter the name of the field in the query result to be used for checkpointing. This field has to be increasing and of type number or timestamp.
- Checkpoint Start. Enter the first value for the checkpoint that the integration will plug into the query.
- (Optional) Time Field. Enter the name of the field in the query result to be parsed as timestamp. If not provided, the current time will be used.
- Query. Enter the query that you need to run. You must include the phrase
%CHECKPOINT%and sort the checkpoint field. - (Optional) Query Interval. Enter the time interval to run the query in the format:
Xm(for X minutes) orXh(for X hours). - Google BigQuery Credential. Upload the Credential JSON file downloaded from Google Cloud IAM & Admin.
- (Optional) Processing Rules for Logs. Configure any desired filters, such as allowlist, denylist, hash, or mask, as described in Create a Processing Rule.
- When you are finished configuring the Source, click Save.
Sample values for Query, Checkpoint, and Checkpoint Start fields
Each query must contain a phrase %CHECKPOINT%. Integration will extract and save the current checkpoint and use it in place of this phrase. The value of Checkpoint Start must be the same type as the Checkpoint Field.
Quote the phrase as "%CHECKPOINT%" if the Checkpoint Field is a timestamp string.
Following are some examples that demonstrate what values to use for the Query, Checkpoint, Time Field, and Checkpoint Start fields.
Example 1: Checkpoint Field is timestamp.
You can see double quotes for the timestamp as it is a string.
Select * from MyProject.MyDataSet.MyTable where timestamp > "%CHECKPOINT%"
| Field | Value |
|---|---|
Checkpoint Field | timestamp |
Checkpoint Start | 2022-02-02 11:00:00.000+0700 |
Time Field | timestamp |
Specific example on a public dataset:
SELECT base_url,source_url,collection_category,collection_number,timestamp(sensing_time) as sensing_time FROM bigquery-public-data.cloud_storage_geo_index.landsat_index where sensing_time > '%CHECKPOINT%' order by sensing_time asc LIMIT 100
| Field | Value |
|---|---|
Checkpoint Field | sensing_time |
Checkpoint Start | 2022-02-02 11:00:00.000+0700 |
Time Field | sensing_time |
Example 2: Checkpoint Field is a numeric field.
SELECT trip_id,subscriber_type,start_time,duration_minutes FROM bigquery-public-data.austin_bikeshare.bikeshare_trips where trip_id > %CHECKPOINT% order by start_time asc LIMIT 100
| Field | Value |
|---|---|
Checkpoint Field | trip_id |
Checkpoint Start | 0 |
Time Field | start_time |
Example 3: Query Gmail Logs
In the example below, you'll need to replace MyProject and MyDataSet with values matching your environment.
SELECT gmail.message_info,gmail.event_info,gmail.event_info.timestamp_usec AS TIMESTAMP FROM `MyProject.MyDataSet.activity` WHERE gmail.event_info.timestamp_usec > %CHECKPOINT% order by TIMESTAMP LIMIT 30000
| Field | Value |
|---|---|
Checkpoint Field | TIMESTAMP |
Checkpoint Start | 1683053865563258 |
Time Field | TIMESTAMP |
Note that the value of Checkpoint Start above is an epoch MICRO seconds timestamp (16 digits) for May 2, 2023 06:57:45.563258 PM GMT and the query also sorts by the checkpoint field (TIMESTAMP).
When setting up this source for Gmail logs for the first time and collecting historical Gmail logs, it is important to set the Checkpoint Start in epoch microseconds (16 digits), and sort the checkpoint field explicitly in your query. Also note that it might take a long time for the source (and many BigQuery queries to execute) to backfill if the starting point is set far in the past - depending on your Gmail logs volume.
JSON schema
Sources can be configured using UTF-8 encoded JSON files with the Collector Management API. See how to use JSON to configure Sources for details.
| Parameter | Type | Value | Required | Description |
|---|---|---|---|---|
| schemaRef | JSON Object | {"type":"Google BigQuery"} | Yes | Define the specific schema type. |
| sourceType | String | "Universal" | Yes | Type of source. |
| config | JSON Object | Configuration object | Yes | Source type specific values. |
Configuration Object
| Parameter | Type | Required | Default | Description | Example |
|---|---|---|---|---|---|
| name | String | Yes | null | Type a desired name of the source. The name must be unique per Collector. This value is assigned to the metadata field _source. | "mySource" |
| description | String | No | null | Type a description of the source. | "Testing source" |
| category | String | No | null | Type a category of the source. This value is assigned to the metadata field _sourceCategory. See best practices for details. | "mySource/test" |
| fields | JSON Object | No | null | JSON map of key-value fields (metadata) to apply to the Collector or Source. Use the boolean field _siemForward to enable forwarding to SIEM. | {"_siemForward": false, "fieldA": "valueA"} |
| projectId | String | Yes | null | The project ID is the globally unique identifier for your project. For example, pelagic-quanta-364805. | |
| credentialsJson | String | Yes | null | This field contains the credential JSON of the Service Account used for accessing BigQuery service. | |
| Query | String | Yes | null | The query to be used in BigQuery. The special string %CHECKPOINT% will be replaced with the largest value seen in the checkpoint field. | |
| timeField | String | No | null | The name of the column to be used to extract timestamp. If not specified, the C2C will use the current time for each row or record we collect. The TIMESTAMP data type is recommended, but any number type will be converted into a epoch milliseconds or epoch microseconds. | |
| checkpointField | String | Yes | null | The column whose largest value will be used as the %CHECKPOINT% in the next search. The checkpoint field has to be of type number of timestamp. | |
| checkpointStart | String | Yes | null | The very first value of the checkpoint to be used in the query. |
JSON example
loading...
Terraform example
loading...
FAQ
Click here for more information about Cloud-to-Cloud sources.